
Fournir des fonctionnalités d'apprentissage automatique précises, cohérentes et prêtes pour la production.

Cet article explore plus en détail notre magasin de fonctionnalités d’apprentissage automatique (ML). Il s'agit d'une continuation de notre article de blog précédent qui fournit un aperçu plus large de l'ensemble de l'infrastructure du pipeline ML.
Pourquoi utilisons-nous un magasin de fonctionnalités ?
Le magasin de fonctionnalités, l’un des nombreux éléments de notre pipeline, est sans doute le rouage le plus important du système. Son objectif principal est de fonctionner comme une base de données centrale qui gère les fonctionnalités avant qu'elles ne soient expédiées pour la formation ou l'inférence du modèle.
Si vous n'êtes pas familier avec le terme, les fonctionnalités sont essentiellement des données brutes qui sont affinées, via un processus appelé ingénierie des fonctionnalités, en quelque chose de plus utilisable que nos modèles ML peuvent utiliser pour s'entraîner ou calculer des prédictions.
En un mot, les feature stores nous permettent de :
Réutilisez et partagez des fonctionnalités entre différents modèles et équipes
Réduisez le temps requis pour les expériences de ML
Minimiser les prédictions inexactes dues à un important décalage entre l'entraînement et la diffusion
Pour mieux comprendre l'importance d'un magasin de fonctionnalités, voici un schéma d'un pipeline ML qui n'en utilise pas.
Dans ce pipeline, les deux parties (formation de modèles et service d'inférence) sont incapables d'identifier les fonctionnalités déjà existantes et pouvant être réutilisées. Cela conduit le pipeline ML à dupliquer le processus d'ingénierie des fonctionnalités. Vous remarquerez dans le cercle rouge sur le diagramme que le pipeline ML, au lieu de réutiliser des fonctionnalités, a créé un ensemble de fonctionnalités en double et de pipelines redondants. Nous appelons cet ensemble un étalement du pipeline de fonctionnalités.
Maintenir cette prolifération de fonctionnalités devient un scénario de plus en plus coûteux et ingérable à mesure que l'entreprise se développe et que de plus en plus d'utilisateurs accèdent à la plateforme. Pensez-y de cette façon; le data scientist doit démarrer le processus d'ingénierie des fonctionnalités, qui est long et fastidieux, entièrement à partir de zéro pour chaque nouveau modèle qu'il crée.
De plus, une réimplémentation excessive de la logique des fonctionnalités introduit un concept appelé biais de formation et de diffusion, qui est un écart entre les données pendant la phase de formation et d'inférence. Cela conduit à des prédictions inexactes et à un comportement imprévisible du modèle, difficile à résoudre pendant la production. Avant les magasins de fonctionnalités, nos data scientists vérifiaient la cohérence des fonctionnalités à l'aide de contrôles d'intégrité. Il s’agit d’un processus manuel et fastidieux qui détourne l’attention des tâches plus prioritaires telles que la modélisation et l’ingénierie approfondie des fonctionnalités. Explorons maintenant un pipeline ML avec un magasin de fonctionnalités.

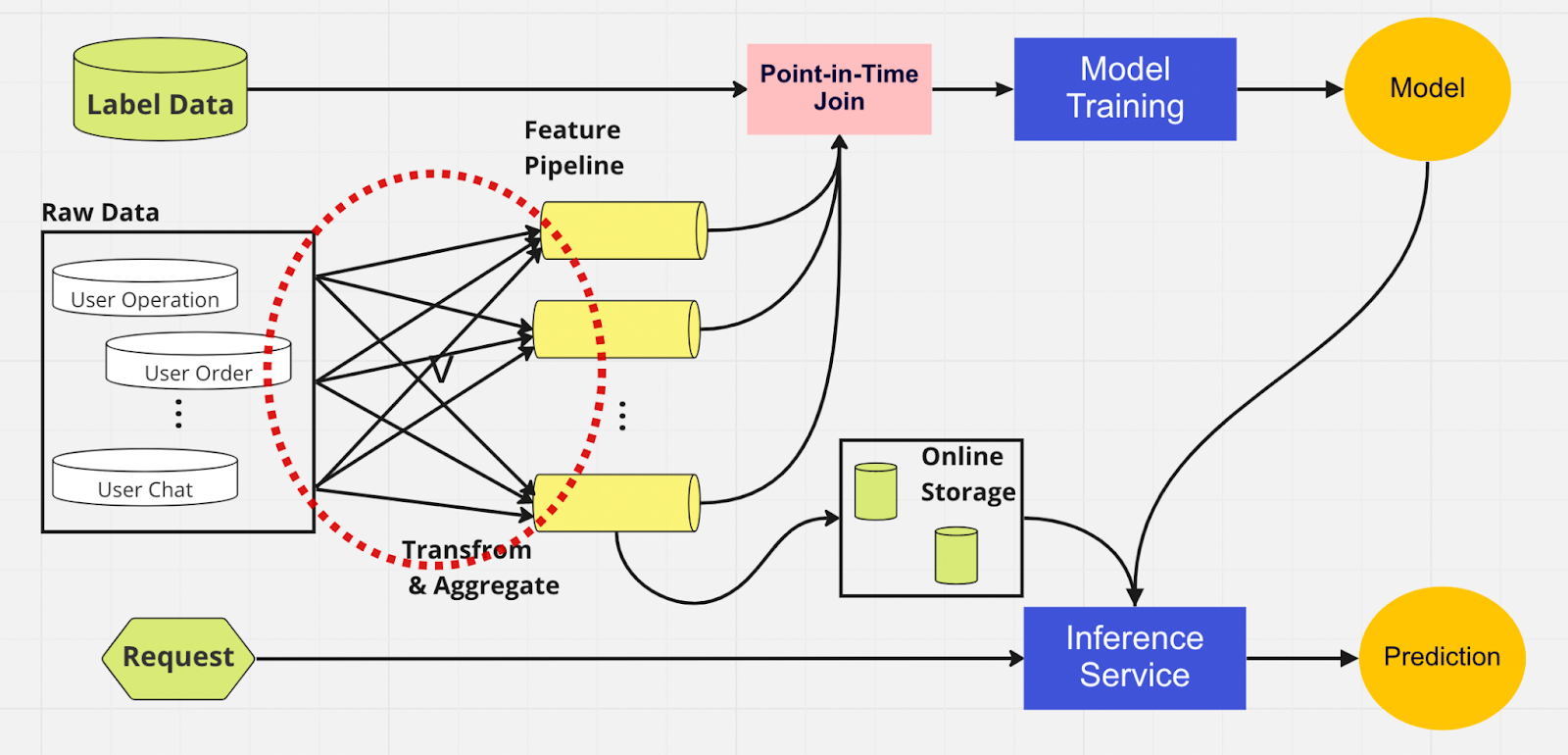
Semblable à l’autre pipeline, nous avons les mêmes sources de données et fonctionnalités sur le côté gauche. Cependant, au lieu de passer par plusieurs pipelines de fonctionnalités, nous avons le magasin de fonctionnalités comme hub central qui dessert les deux phases du pipeline ML (formation de modèles et service d'inférence). Il n’y a pas de fonctionnalités en double ; tous les processus requis pour créer une fonctionnalité, y compris la transformation et l'agrégation, ne doivent être effectués qu'une seule fois.
Les data scientists peuvent interagir intuitivement avec le magasin de fonctionnalités à l'aide de notre SDK Python personnalisé pour rechercher, réutiliser et découvrir des fonctionnalités pour la formation et l'inférence de modèles ML en aval.
Essentiellement, le magasin de fonctionnalités est une base de données centralisée qui unifie les deux phases. Et comme le magasin de fonctionnalités garantit des fonctionnalités cohérentes pour la formation et l’inférence, nous pouvons réduire considérablement le décalage entre la formation et la diffusion.
Notez que les magasins de fonctionnalités font bien plus que les points mentionnés ci-dessus. Il s'agit bien sûr d'un résumé plus rudimentaire de la raison pour laquelle nous utilisons un magasin de fonctionnalités et que nous pouvons décomposer en quelques mots : préparer et envoyer des fonctionnalités dans des modèles ML de la manière la plus rapide et la plus simple possible.
À l'intérieur du magasin de fonctionnalités

La figure ci-dessus montre la disposition typique de votre magasin de fonctionnalités, qu'il s'agisse d'AWS SageMaker Feature Store, de Google vertex AI (Feast), Azure (Feathr), Iguazio ou Tetcom. Tous les magasins de fonctionnalités proposent deux types de stockage : en ligne ou hors ligne.
Les magasins de fonctionnalités en ligne sont utilisés pour l'inférence en temps réel, tandis que les magasins de fonctionnalités hors ligne sont utilisés pour la prédiction par lots et la formation de modèles. En raison des différents cas d'utilisation, la métrique que nous utilisons pour évaluer les performances est totalement différente. Dans une fonctionnalité en ligne, nous recherchons une faible latence. Pour les magasins de fonctionnalités hors ligne, nous souhaitons un débit élevé.
Les développeurs peuvent choisir n'importe quel magasin de fonctionnalités d'entreprise ou même open source en fonction de la pile technologique. Le diagramme ci-dessous présente les principales différences entre les magasins en ligne et hors ligne dans AWS SageMaker Feature Store.

Boutique en ligne : stocke la copie la plus récente des fonctionnalités et les diffuse avec une latence faible en millisecondes, dont la vitesse dépend de la taille de votre charge utile. Pour notre modèle de prise de contrôle de compte (ATO), qui comporte huit groupes de fonctionnalités et 55 fonctionnalités au total, la vitesse est d'environ 30 ms de latence p99.
Boutique hors ligne : une boutique en ajout uniquement qui vous permet de suivre toutes les caractéristiques historiques et de permettre le voyage dans le temps pour éviter les fuites de données. Les données sont stockées au format parquet avec partition temporelle pour augmenter l'efficacité de la lecture.
Concernant la cohérence des fonctionnalités, tant que le groupe de fonctionnalités est configuré pour une utilisation en ligne et hors ligne, les données seront automatiquement et en interne copiées dans la boutique hors ligne pendant que la fonctionnalité est ingérée par la boutique en ligne.
Comment utilisons-nous le Feature Store ?

Le code illustré ci-dessus cache beaucoup de complexité. Les magasins de fonctionnalités nous permettent d'importer simplement l'interface Python pour la formation et l'inférence du modèle.
Grâce au magasin de fonctionnalités, nos data scientists peuvent facilement définir des fonctionnalités et créer de nouveaux modèles sans avoir à se soucier du processus fastidieux d'ingénierie des données dans le backend.
Meilleures pratiques d'utilisation d'un magasin de fonctionnalités
Dans notre précédent article de blog, nous avons expliqué comment nous utilisons une couche de magasin pour canaliser les fonctionnalités vers la base de données centralisée. Ici, nous aimerions partager deux bonnes pratiques lors de l’utilisation d’un magasin de fonctionnalités :
Nous n’ingérons pas les fonctionnalités qui n’ont pas changé
Nous séparons les fonctionnalités en deux groupes logiques : les opérations utilisateur actives et les opérations inactives.
Considérez cet exemple. Disons que vous disposez d'une limite de limitation de 10 000 TPS pour PutRecord sur votre boutique de fonctionnalités en ligne. En utilisant cette hypothèse, nous ingérerons des fonctionnalités pour 100 millions d’utilisateurs. Nous ne pouvons pas tous les ingérer en même temps, et avec notre vitesse actuelle, cela prendra environ 2,7 heures pour terminer. Pour résoudre ce problème, nous choisissons uniquement d’ingérer les fonctionnalités récemment mises à jour. Par exemple, nous n’ingérerons pas une fonctionnalité si la valeur n’a pas changé depuis la dernière fois qu’elle a été ingérée.
Pour le deuxième point, disons que vous placez un ensemble de fonctionnalités dans un groupe de fonctionnalités logique. Certaines sont actives, tandis qu’une grande partie est inactive, ce qui signifie que la plupart des fonctionnalités restent inchangées. L'étape logique, à notre avis, consiste à diviser les actifs et les inactifs en deux groupes de fonctionnalités pour accélérer le processus d'ingestion.
Pour les fonctionnalités inactives, nous réduisons 95 % des données que nous devons ingérer dans le magasin de fonctionnalités pour 100 millions d'utilisateurs sur une base horaire. De plus, nous réduisons toujours de 20 % les données requises pour les fonctionnalités actives. Ainsi, au lieu de trois heures, le pipeline d’ingestion par lots traite les fonctionnalités de 100 millions d’utilisateurs en 10 minutes.
Pensées finales
Pour résumer, les magasins de fonctionnalités nous permettent de réutiliser des fonctionnalités, d'accélérer l'ingénierie des fonctionnalités et de minimiser les prédictions inexactes, tout en maintenant la cohérence entre la formation et l'inférence.
Vous souhaitez utiliser le ML pour protéger le plus grand écosystème cryptographique au monde et ses utilisateurs ? Consultez Binance Engineering/AI sur notre page Carrières pour les offres d'emploi ouvertes.
Lectures complémentaires :
(Blog) Utiliser MLOps pour créer un pipeline d'apprentissage automatique de bout en bout en temps réel