
Menghadirkan fitur pembelajaran mesin yang akurat, konsisten, dan siap produksi.

Bagian ini mengeksplorasi penyimpanan fitur pembelajaran mesin (ML) kami secara lebih detail. Ini merupakan kelanjutan dari postingan blog kami sebelumnya yang memberikan gambaran lebih luas tentang keseluruhan infrastruktur pipeline ML.
Mengapa Kami Menggunakan Toko Fitur?
Penyimpanan fitur, salah satu dari banyak bagian dalam saluran kami, bisa dibilang merupakan roda penggerak paling penting dalam sistem. Tujuan utamanya adalah berfungsi sebagai database pusat yang mengelola fitur sebelum dikirim untuk pelatihan model atau inferensi.
Jika Anda belum familiar dengan istilah ini, fitur pada dasarnya adalah data mentah yang disempurnakan, melalui proses yang disebut rekayasa fitur, menjadi sesuatu yang lebih bermanfaat sehingga model ML kami dapat digunakan untuk melatih dirinya sendiri atau menghitung prediksi.
Singkatnya, toko fitur memungkinkan kita untuk:
Gunakan kembali dan bagikan fitur ke berbagai model dan tim
Mempersingkat waktu yang diperlukan untuk eksperimen ML
Meminimalkan prediksi yang tidak akurat karena penyimpangan penyajian pelatihan yang parah
Untuk lebih memahami pentingnya penyimpanan fitur, berikut adalah diagram pipeline ML yang tidak menggunakan fitur tersebut.
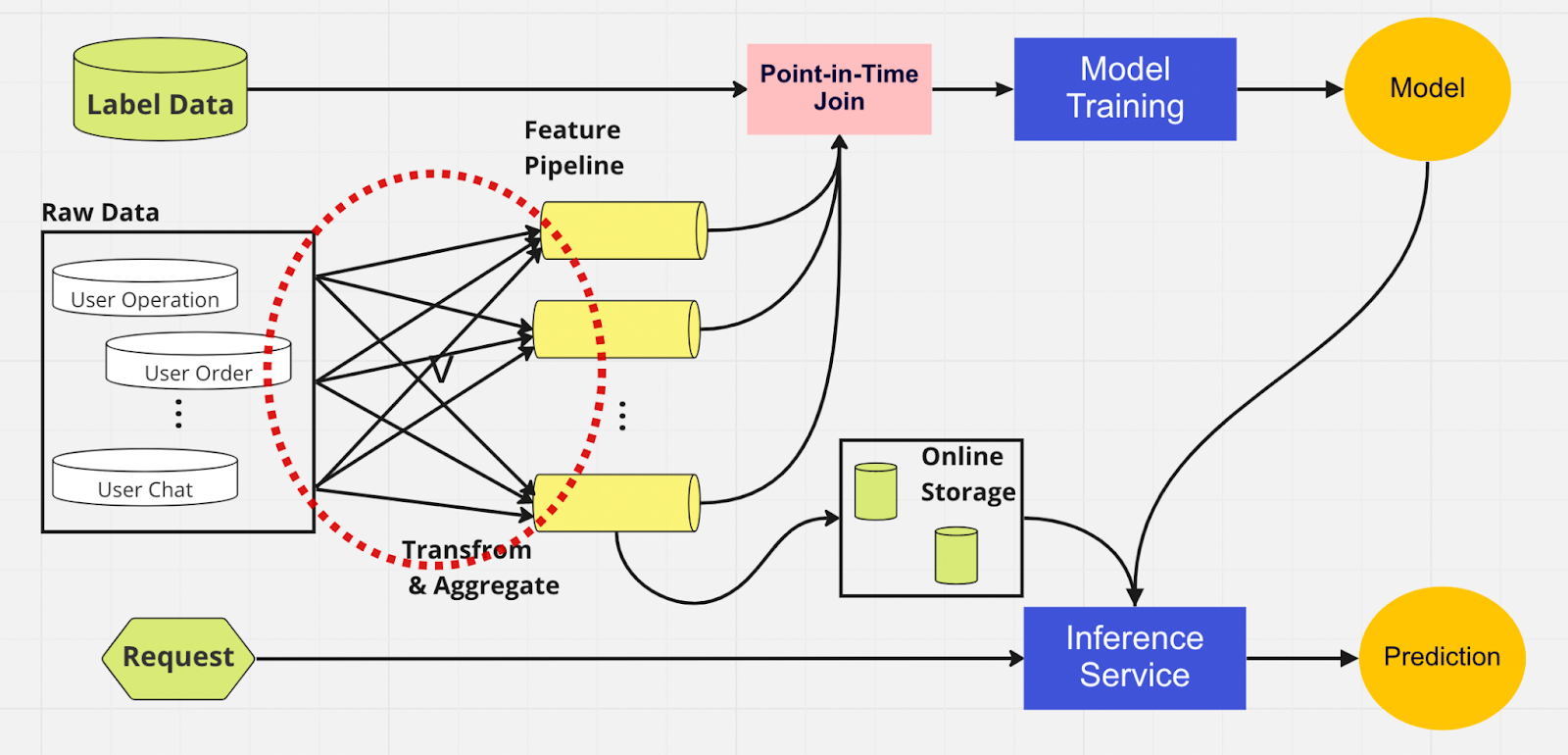
Dalam pipeline ini, dua bagian — pelatihan model dan layanan inferensi — tidak dapat mengidentifikasi fitur mana yang sudah ada dan dapat digunakan kembali. Hal ini menyebabkan pipeline ML menduplikasi proses rekayasa fitur. Anda akan melihat dalam lingkaran merah pada diagram bahwa pipeline ML, alih-alih menggunakan kembali fitur, malah membangun sekumpulan fitur duplikat dan pipeline yang berlebihan. Kami menyebut rumpun ini sebagai perluasan jalur pipa fitur.
Mempertahankan fitur-fitur yang luas ini menjadi skenario yang semakin mahal dan tidak dapat dikelola seiring dengan pertumbuhan bisnis dan semakin banyak pengguna yang memasuki platform. Pikirkan seperti ini; ilmuwan data harus memulai proses rekayasa fitur, yang panjang dan membosankan, sepenuhnya dari awal untuk setiap model baru yang mereka buat.
Selain itu, terlalu banyak implementasi ulang logika fitur menimbulkan konsep yang disebut kemiringan penyajian pelatihan, yang merupakan perbedaan antara data selama tahap pelatihan dan inferensi. Hal ini menyebabkan prediksi yang tidak akurat dan perilaku model yang tidak dapat diprediksi sehingga sulit dipecahkan selama produksi. Sebelum fitur disimpan, ilmuwan data kami akan memeriksa konsistensi fitur menggunakan pemeriksaan kewarasan. Ini adalah proses manual dan memakan waktu yang mengalihkan perhatian dari tugas-tugas dengan prioritas lebih tinggi seperti pemodelan dan rekayasa fitur yang mendalam. Sekarang, mari kita jelajahi pipeline ML dengan penyimpanan fitur.

Mirip dengan pipeline lainnya, kami memiliki sumber data dan fitur yang sama di sisi kiri. Namun, alih-alih melalui beberapa saluran fitur, kami memiliki penyimpanan fitur sebagai satu hub pusat yang melayani kedua fase saluran ML (pelatihan model dan layanan inferensi). Tidak ada fitur duplikat; semua proses yang diperlukan untuk membangun sebuah fitur, termasuk transformasi dan agregasi, hanya perlu dilakukan satu kali.
Ilmuwan data dapat berinteraksi secara intuitif dengan penyimpanan fitur menggunakan SDK Python kami yang dibuat khusus untuk mencari, menggunakan kembali, dan menemukan fitur untuk pelatihan dan inferensi model ML hilir.
Pada dasarnya, penyimpanan fitur adalah database terpusat yang menyatukan kedua fase. Dan karena penyimpanan fitur menjamin fitur yang konsisten untuk pelatihan dan inferensi, kami dapat mengurangi kemiringan penyajian pelatihan secara signifikan.
Perhatikan bahwa toko fitur melakukan lebih dari sekadar poin yang kami sebutkan di atas. Tentu saja, ini adalah ringkasan yang lebih mendasar tentang alasan kami menggunakan penyimpanan fitur dan ringkasan yang dapat kami uraikan lebih lanjut menjadi beberapa kata saja: menyiapkan dan mengirimkan fitur ke dalam model ML dengan cara tercepat dan termudah.
Di dalam Toko Fitur

Gambar di atas menunjukkan tata letak penyimpanan fitur khas Anda, baik itu AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio, atau Tetcom. Semua toko fitur menyediakan dua jenis penyimpanan: online atau offline.
Penyimpanan fitur online digunakan untuk inferensi waktu nyata, sedangkan penyimpanan fitur offline digunakan untuk prediksi batch dan pelatihan model. Karena kasus penggunaan yang berbeda, metrik yang kami gunakan untuk mengevaluasi kinerja sepenuhnya berbeda. Dalam fitur online, kami mencari latensi rendah. Untuk toko fitur offline, kami menginginkan throughput yang tinggi.
Pengembang dapat memilih toko fitur perusahaan mana pun atau bahkan sumber terbuka berdasarkan tumpukan teknologi. Diagram di bawah menguraikan perbedaan utama antara toko online dan offline di AWS SageMaker Feature Store.

Toko online: Menyimpan salinan fitur terbaru dan menyajikannya dengan latensi milidetik rendah, yang kecepatannya bergantung pada ukuran payload Anda. Untuk model pengambilalihan akun (ATO) kami, yang memiliki delapan grup fitur dan total 55 fitur, kecepatan latensinya sekitar 30 ms p99.
Toko offline: Toko khusus tambahan yang memungkinkan Anda melacak semua fitur historis dan mengaktifkan perjalanan waktu untuk menghindari kebocoran data. Data disimpan dalam format parket dengan partisi waktu untuk meningkatkan efisiensi membaca.
Mengenai konsistensi fitur, selama grup fitur dikonfigurasi untuk penggunaan online dan offline, data akan disalin secara otomatis dan internal ke toko offline saat fitur tersebut diserap oleh toko online.
Bagaimana Kami Menggunakan Feature Store?

Kode yang digambarkan di atas menyembunyikan banyak kerumitan. Penyimpanan fitur memungkinkan kita mengimpor antarmuka python untuk pelatihan model dan inferensi.
Dengan menggunakan penyimpanan fitur, ilmuwan data kami dapat dengan mudah menentukan fitur dan membuat model baru tanpa harus khawatir tentang proses rekayasa data yang membosankan di backend.
Praktik Terbaik untuk Menggunakan Feature Store
Dalam postingan blog kami sebelumnya, kami menjelaskan bagaimana kami menggunakan lapisan penyimpanan untuk menyalurkan fitur ke dalam DB terpusat. Di sini, kami ingin berbagi dua praktik terbaik saat menggunakan toko fitur:
Kami tidak menyerap fitur yang tidak berubah
Kami memisahkan fitur menjadi dua kelompok logis: operasi pengguna aktif dan tidak aktif
Perhatikan contoh ini. Katakanlah Anda memiliki batas pembatasan TPS 10K untuk PutRecord di toko fitur online Anda. Dengan menggunakan hipotesis ini, kami akan menyerap fitur untuk 100 juta pengguna. Kami tidak dapat menyerap semuanya sekaligus, dan dengan kecepatan kami saat ini, diperlukan waktu sekitar 2,7 jam untuk menyelesaikannya. Untuk mengatasi hal ini, kami memilih hanya untuk menyerap fitur yang baru saja diperbarui. Misalnya, kami tidak akan menyerap fitur jika nilainya tidak berubah sejak terakhir kali fitur tersebut diserap.
Untuk poin kedua, katakanlah Anda memasukkan sekumpulan fitur ke dalam satu grup fitur logis. Ada yang aktif, dan sebagian besar tidak aktif, artinya sebagian besar fitur tidak berubah. Langkah logisnya, menurut kami, adalah membagi aktif dan tidak aktif menjadi dua kelompok fitur untuk mempercepat proses penyerapan.
Untuk fitur yang tidak aktif, kami mengurangi 95% data yang diperlukan untuk dimasukkan ke dalam penyimpanan fitur untuk 100 juta pengguna setiap jam. Selain itu, kami masih mengurangi 20% data yang diperlukan untuk fitur aktif. Jadi, alih-alih memakan waktu tiga jam, alur penyerapan batch memproses fitur senilai 100 juta pengguna dalam 10 menit.
Menutup Pikiran
Ringkasnya, penyimpanan fitur memungkinkan kami menggunakan kembali fitur, mempercepat rekayasa fitur, dan meminimalkan prediksi yang tidak akurat — sambil menjaga konsistensi antara pelatihan dan inferensi.
Tertarik menggunakan ML untuk melindungi ekosistem kripto terbesar di dunia dan penggunanya? Lihat Binance Engineering/AI di halaman karir kami untuk lowongan pekerjaan terbuka.
Bacaan lebih lanjut:
(Blog) Menggunakan MLOps untuk Membangun Pipeline Machine Learning End-to-End Secara Real-time