Continuando con los dos artículos anteriores sobre asuntos que requieren atención en el comercio programático:
Productos secos básicos: detalles y reflexiones sobre el comercio automatizado en tiempo real de sistemas de comercio cuantitativos (1. Problemas y dificultades)
Sistema de negociación cuantitativa: pensamientos y detalles de la oferta en firme automatizada (2. Propósito de la oferta en firme)
Aquí continuaremos hablando sobre algunas habilidades de manejo detalladas en el diseño de código.
base de datos
Como se mencionó en los dos artículos anteriores, el registro de estado de una combinación de estrategias más compleja es muy importante y requiere el uso de una base de datos.
De hecho, la mayoría de las empresas de programación se pueden clasificar en la categoría CRUD, es decir, el proceso central es simplemente agregar, eliminar, modificar y verificar la base de datos. Los códigos comerciales no son una excepción. En realidad, el comportamiento de las operaciones en los mercados secundarios de frecuencia media y baja no es muy diferente de cuando las personas van a comprar un determinado tesoro. El objetivo de las operaciones automatizadas radica en la gestión del estado estratégico.
Si aún no está familiarizado con las bases de datos relacionales como SQL, se recomienda que aprenda directamente a utilizar bases de datos en memoria NoSQL como Redis. Sus ventajas son que es fácil de comenzar, tiene un rendimiento excelente y es inherentemente de un solo subproceso. No es necesario considerar operaciones de bajo nivel, como bloquear datos al leer y escribir. Sin embargo, la desventaja es que no existe una clave principal y no se pueden realizar funciones como el incremento automático de números. Si es necesario, deberá escribir código para implementarlo usted mismo. Sin embargo, nunca había usado esta función en el comercio automatizado durante tanto tiempo.
Otra cuestión sin importancia es que para las bases de datos en memoria, si la cantidad de datos que deben almacenarse es relativamente grande, entonces la memoria del servidor debe ser mayor. Sin embargo, para el comercio cuantitativo general, 4G o incluso 2G de memoria son suficientes y son suficientes. No es necesario. Ahorre tantos datos.
Redis es realmente poderoso en el mundo real. Si su estrategia tiene requisitos de alta frecuencia, también puede implementar el modelo de suscripción de mensajes pub/sub, eliminando la necesidad de agregar varios módulos MQ adicionales. Si usa una base de datos relacional como MySQL, como se mencionó anteriormente, siempre que no la haya usado en la práctica antes, tendrá que invertir tiempo y energía en aprender SQL, un lenguaje de programación relativamente desagradable y difícil. Tenga en cuenta que todo el mundo está aquí para realizar operaciones cuantitativas, no para aprender a escribir código. Intente utilizar una solución más sencilla.
Además, si desea construir un centro de mercado, teniendo en cuenta el rendimiento, también utilizará la base de datos de Redis y cooperará con la cola de mensajes por conveniencia. La solución es sencilla y adecuada para la mayoría de escenarios. Se puede utilizar un servidor (o varios servidores).
diseño de código
Básicamente, al escribir código, la estructura de datos central es la más importante. El diseño de la estructura de datos no es lo suficientemente razonable y el código se escribirá de manera incómoda, porque inevitablemente hará que los distintos módulos se acoplen, lo que hará que las modificaciones sean muy problemáticas. Pero para diseñarlo correctamente, se necesita cierta experiencia comercial, es decir, experiencia empresarial. Todo esto trata sobre cómo escribir código, no hay mucho que decir. Las estrategias de cada uno son diferentes y no pueden tratarse por igual. Sin embargo, algunos principios probablemente sean los mismos.
Por ejemplo, después de enviar una orden, no hay garantía de éxito, incluso si es una orden de mercado, porque el intercambio puede rechazarla. Por ejemplo, la central está demasiado ocupada o se produce una pérdida temporal de paquetes de datos de la red. Entonces, es mejor diseñar algunos estados intermedios similares al compromiso de 2 fases. Si falla, seguirá intentándolo (por supuesto, no con demasiada frecuencia; de lo contrario, se le prohibirá si excede el límite). Hay un decorador de reintento especial para hacerlo. this), o agregue más métodos para corregir el estado de error.
En circunstancias normales, incluso si el intercambio cae, se recuperará en poco tiempo. Si no se recupera, una de las partes quedará completamente inactiva, ya sea el intercambio o su propio servidor de códigos. Esto debe ser monitoreado y alertado. Es imposible que el código automatizado cubra todo. Si no se puede procesar automáticamente, se emitirá una alarma. Si el procesamiento manual no se maneja a tiempo, mientras no sigamos abriendo posiciones para aumentar la exposición, el problema no será demasiado grande, porque existen órdenes algorítmicas de stop-loss para cubrir el fondo.
La siguiente es una lógica de apertura estratégica que resolví yo mismo:
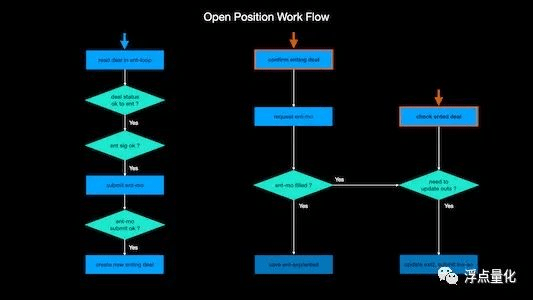
Básicamente, al dibujar un diagrama de flujo similar, el código estará mucho más organizado y se reducirá la cantidad de errores potenciales. Por lo tanto, antes de escribir código, es mejor dibujar un diagrama de flujo o ordenarlo mientras escribe, para que la lógica sea clara y tenga una idea.
La lógica de cerrar una posición es mucho más complicada que esto, porque existen más condiciones para cerrar una posición, como stop-profit, stop-loss y señales de salida de varias estrategias, que desencadenarán el cierre de la posición. En resumen, la importancia de la salida es mayor que la de la entrada, y la oferta real también es un poco más problemática.
Debido a que la lógica estratégica de cada uno es definitivamente diferente, no entraré en detalles aquí. Lo principal es enderezar su lógica estratégica y evitar que se produzcan varios posibles errores.
Sin embargo, estos parecen complicados y son solo un montón de if else (Python ni siquiera tiene una declaración de cambio). Si se cumplen las condiciones, continúe con el siguiente paso. Si no, salga, no hay gran problema.
control del tiempo
Al realizar transacciones, el tiempo es sin duda muy importante. Aquí compartiré algunas de mis habilidades de control del tiempo.
En la programación general, si hay tareas que deben ejecutarse con regularidad, generalmente se utilizan paquetes de trabajos cron como apscheduler. Por ejemplo, planifique una tarea programada para detectar si el precio de la línea K necesita abrir o cerrar una posición tan pronto como llegue la hora.
Este tipo de paquete en realidad abre un nuevo hilo inmediatamente a la hora establecida (puede tener una precisión del segundo nivel) y luego ejecuta la tarea especificada. El problema es que si el tiempo de ejecución de esta tarea es demasiado largo, se procederá a la siguiente tarea. Comenzará de nuevo. Habrá problemas. Aunque se pueden resolver, son más problemáticos.
Por lo general, uso este tipo de tareas programadas cuando necesito generar información de registro con regularidad y realizar la autocorrección y autoprueba del programa, que son funciones de baja frecuencia que se pueden completar rápidamente. Estas funciones solo leen los datos en la base de datos y no hay operaciones de escritura o actualización, por lo que no está de más permitir que Apscheduler abra otro hilo para su procesamiento.
Sin embargo, la lógica que requiere consultas constantes y frecuentes de los precios del mercado o del estado de las políticas locales no es adecuada para tal paquete de sincronización y necesita ser controlada por un bucle while.
Por ejemplo, si la estrategia utiliza señales dentro de la barra de la línea K, significa que la señal puede aparecer en cualquier momento y es necesario comprobar constantemente el precio subyacente o el volumen de operaciones para determinar si es necesario realizar las operaciones correspondientes. Si necesita un control de tiempo más preciso en este momento, por ejemplo, solo ejecute la lógica de serie de abrir una posición 10 segundos antes del final de la hora de la línea k. Entonces, ¿cómo puedes juzgar simplemente si son los últimos 10 segundos?
Tomé el resto de 3600 usando la marca de tiempo.
(Si no está familiarizado con la marca de tiempo en la computadora, es decir, la marca de tiempo, comienza en la hora media de Greenwich 1970.1.1. Por ejemplo, es aproximadamente el 1691240298 segundo. No hay ningún problema con que la computadora sea precisa hasta el nivel de microsegundos.)
Después de tomar el resto de 3600, si el resto es mayor que 3590 segundos, son los últimos diez segundos. El error puede reducirse al nivel de milisegundos. Como se mencionó anteriormente, es mejor que las operaciones de transacción principales se ejecuten secuencialmente en un hilo. De esta manera, el tiempo de ejecución se puede controlar de manera aproximada o el período de tiempo puede ser borroso, lo cual no será un problema.
Este tipo de control requiere que la configuración horaria de su propio servidor no se desvíe mucho de la hora estándar. Sin embargo, este tipo de control no será muy preciso y solo podrá llegar al segundo nivel. Sin embargo, Python no puede controlar el tiempo con mucha precisión y esas funciones de suspensión provocarán errores de aproximadamente microsegundos.
Reducir la frecuencia de acceso a la API
Si ha adoptado un centro de mercado independiente basado en websocket para compartir información pública del mercado, como líneas K, entre diferentes estrategias o incluso diferentes códigos comerciales, entonces no hay preocupación por los límites de frecuencia de API a este respecto.
Pero también necesitamos obtener información de la cuenta de manera oportuna, es decir, tres tipos de información: fondos, posiciones y órdenes. Aunque la información de la cuenta también puede usar websocket y esperar a que el servidor Exchange la impulse activamente, es más sencillo usar directamente la API restante por tres razones.
Primero, para reducir la carga de la información de la cuenta enviada por websocket, el intercambio requiere que se vuelva a conectar o actualice la escucha clave de vez en cuando (Binance dura 60 minutos). Obviamente, esta situación es más problemática de mantener. Aunque no es mucho problema, si aloja API e intercambia varias cuentas al mismo tiempo, debe activar un programa separado para garantizar la precisión de la información en tiempo real, y la lógica se vuelve mucho más complicada.
En segundo lugar, algunos intercambios no tienen websocket push para actualizar la información de la cuenta. En este caso, la lógica comercial no es universal y es más problemático cambiar códigos comerciales reales entre diferentes intercambios. Por supuesto, la mayoría de las personas no operarán en múltiples intercambios y no se encontrarán con tal situación.
En tercer lugar, si el enlace de websocket está roto o encuentra problemas como la actualización o caducidad de listeningKey mencionado anteriormente, si el programa no lo descubre a tiempo y hay una transacción en este momento, entonces si solo confía en websocket, causará un gran problema de comparación, porque la información de actualización de cuenta perdida no se enviará nuevamente. Para evitar la posibilidad de que surjan tales problemas potenciales, también debe confiar en la API restante para obtener cierta información de la cuenta. Entonces, al final, tienes que confiar en la API restante, ¿no es innecesario?
En resumen, para transacciones de media y baja frecuencia, es mejor utilizar directamente la API de descanso para obtener información de la cuenta. Para fuentes de datos importantes, es mejor seguir SSOT (fuente única de verdad); de lo contrario, puede causar confusión. Este concepto puede buscarlo en Google y es muy útil en la programación que depende del procesamiento de datos.
Luego, si solo usa la API REST para obtener información de la cuenta, puede mantener una tabla de información de la cuenta temporal en la memoria del código local, especialmente los fondos disponibles. Esto puede reducir las visitas frecuentes al intercambio. puede enviar todos los pedidos a la vez. De manera similar a realizar pedidos en lotes y luego procesar lentamente la lógica detrás de la actualización, cuanto más rápido se realice el pedido, menor será el deslizamiento.
Además, para determinar si la orden algorítmica de stop-loss se ha ejecutado, puede utilizar los precios máximos y mínimos recientes en lugar de obtener directamente el estado de la orden pendiente, porque para determinar si la orden se ha ejecutado, es necesario sondear continuamente, lo cual es relativamente frecuente y provocará muchos accesos a API no válidos. La actualización del precio de K-line de websocket es muy oportuna y no ocupa el límite de frecuencia API.
Del mismo modo, algunas órdenes de salida también pueden ser así. Si su señal de salida depende del precio dentro de una barra, puede ser mejor utilizar precios máximos y mínimos recientes. Debido a que a veces el precio se dispara y regresa inmediatamente, si su frecuencia de verificación no es demasiado alta, es posible que se lo pierda. Para garantizar la coherencia en su estrategia comercial, verifique los máximos y mínimos para no pasar por alto los precios. Este enfoque tiene el beneficio adicional de que el precio real de la transacción puede ser más favorable que el precio de activación real.
No sé si los dos puntos anteriores son fáciles de entender. Puede que requiera alguna experiencia de la vida real.
Me gustaría compartir algo de mi experiencia en el desarrollo de código real, esperando que sea útil para todos.