
Ofrece funciones de aprendizaje automático precisas, consistentes y listas para producción.

Este artículo explora nuestra tienda de funciones de aprendizaje automático (ML) con más detalle. Es una continuación de nuestra publicación de blog anterior que brinda una descripción general más amplia de toda la infraestructura del proceso de ML.
¿Por qué utilizamos una tienda de funciones?
El almacén de funciones, una de las muchas partes de nuestra cartera, es posiblemente el engranaje más importante del sistema. Su objetivo principal es funcionar como una base de datos central que gestiona las funciones antes de enviarlas para entrenamiento o inferencia del modelo.
Si no está familiarizado con el término, las características son esencialmente datos sin procesar que se refinan, mediante un proceso llamado ingeniería de características, hasta convertirlos en algo más utilizable que nuestros modelos de aprendizaje automático pueden usar para entrenarse a sí mismos o calcular predicciones.
En pocas palabras, las tiendas de funciones nos permiten:
Reutilice y comparta funciones entre diferentes modelos y equipos
Acorte el tiempo necesario para los experimentos de aprendizaje automático
Minimizar las predicciones inexactas debido a un grave sesgo en el servicio de entrenamiento
Para comprender mejor la importancia de una tienda de funciones, aquí hay un diagrama de una canalización de ML que no la utiliza.
En este proceso, las dos partes (entrenamiento de modelos y servicio de inferencia) no pueden identificar qué características ya existen y pueden reutilizarse. Esto lleva a que la canalización de ML duplique el proceso de ingeniería de funciones. Notará en el círculo rojo del diagrama que la canalización de ML, en lugar de reutilizar funciones, ha creado un grupo de funciones duplicadas y canalizaciones redundantes. A este grupo lo llamamos expansión de la cartera de funciones.
Mantener esta proliferación de funciones se convierte en un escenario cada vez más costoso e inmanejable a medida que el negocio crece y más usuarios ingresan a la plataforma. Piensa en ello de esta manera; el científico de datos debe comenzar el proceso de ingeniería de características, que es largo y tedioso, completamente desde cero para cada nuevo modelo que crea.
Además, demasiada reimplementación de la lógica de características introduce un concepto llamado sesgo de servicio de entrenamiento, que es una discrepancia entre los datos durante la etapa de entrenamiento e inferencia. Conduce a predicciones inexactas y a un comportamiento del modelo impredecible que es difícil de solucionar durante la producción. Antes de las tiendas de funciones, nuestros científicos de datos verificaban la coherencia de las funciones mediante controles de cordura. Se trata de un proceso manual que requiere mucho tiempo y que desvía la atención de tareas de mayor prioridad, como el modelado y la ingeniería de características detallada. Ahora, exploremos una canalización de ML con una tienda de funciones.

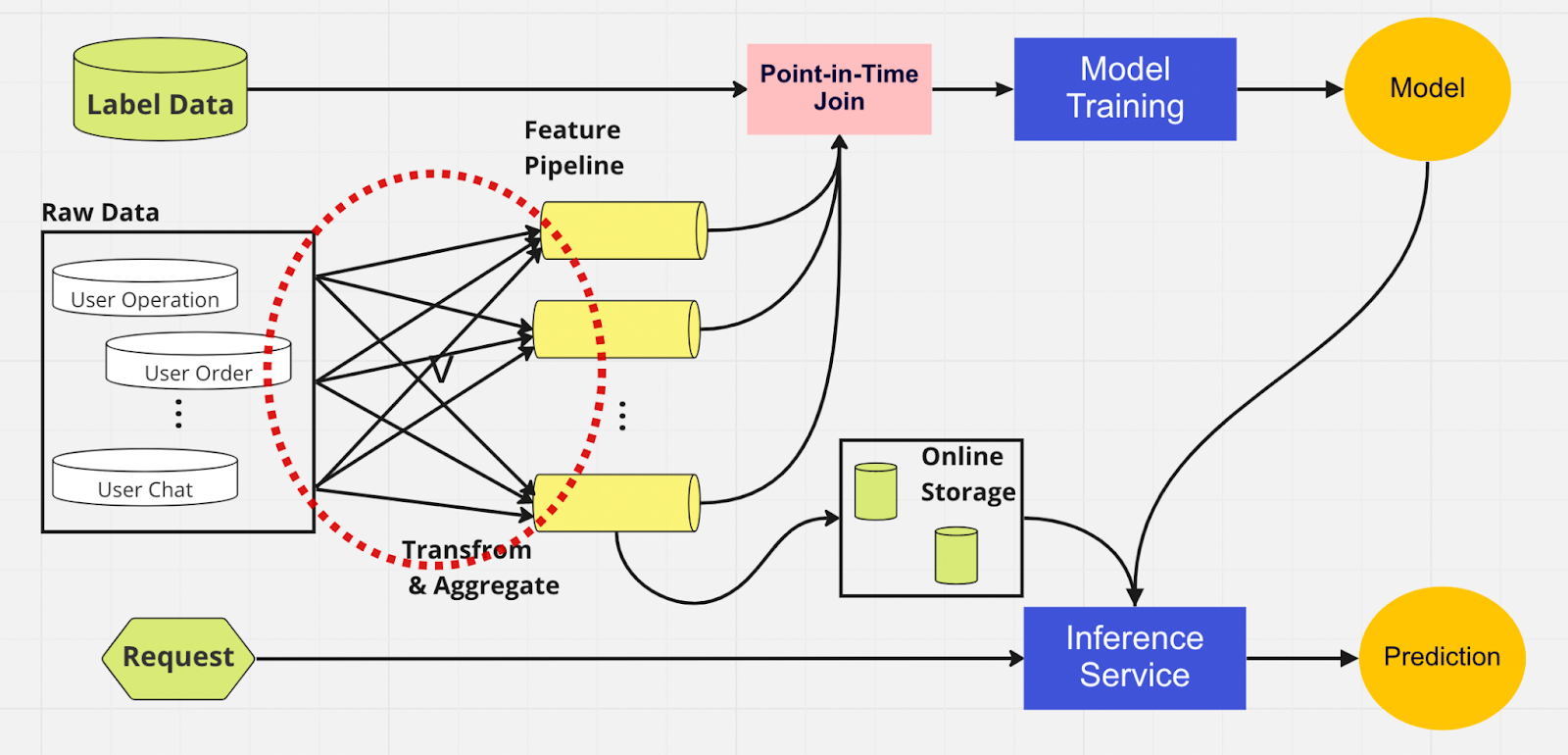
Al igual que en el otro canal, tenemos las mismas fuentes de datos y funciones en el lado izquierdo. Sin embargo, en lugar de pasar por múltiples canales de funciones, tenemos el almacén de funciones como un centro central que sirve a ambas fases del canal de ML (entrenamiento de modelos y servicio de inferencia). No hay funciones duplicadas; Todos los procesos necesarios para crear una característica, incluida la transformación y la agregación, solo deben realizarse una vez.
Los científicos de datos pueden interactuar intuitivamente con el almacén de funciones utilizando nuestro SDK de Python personalizado para buscar, reutilizar y descubrir funciones para la inferencia y el entrenamiento de modelos de aprendizaje automático posteriores.
Básicamente, el almacén de funciones es una base de datos centralizada que unifica ambas fases. Y dado que el almacén de características garantiza características consistentes para el entrenamiento y la inferencia, podemos reducir en gran medida el sesgo en el servicio de entrenamiento.
Tenga en cuenta que las tiendas de funciones hacen mucho más que los puntos que mencionamos anteriormente. Este es, por supuesto, un resumen más rudimentario de por qué usamos un almacén de funciones y que podemos desglosar en unas pocas palabras: preparar y enviar funciones a modelos de aprendizaje automático de la manera más rápida y sencilla posible.
Dentro de la tienda de funciones

La figura anterior muestra el diseño típico de la tienda de funciones, ya sea AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio o Tetcom. Todas las tiendas de funciones ofrecen dos tipos de almacenamiento: en línea o fuera de línea.
Los almacenes de características en línea se utilizan para la inferencia en tiempo real, mientras que los almacenes de características fuera de línea se utilizan para la predicción por lotes y el entrenamiento de modelos. Debido a los diferentes casos de uso, la métrica que utilizamos para evaluar el rendimiento es completamente diferente. En una función en línea, buscamos una latencia baja. Para las tiendas de funciones fuera de línea, queremos un alto rendimiento.
Los desarrolladores pueden elegir cualquier tienda de funciones empresariales o incluso código abierto según la pila tecnológica. El siguiente diagrama describe las diferencias clave entre las tiendas en línea y fuera de línea en AWS SageMaker Feature Store.

Tienda en línea: almacena la copia más reciente de las funciones y las ofrece con una latencia baja de milisegundos, cuya velocidad depende del tamaño de su carga útil. Para nuestro modelo de adquisición de cuenta (ATO), que tiene ocho grupos de funciones y 55 funciones en total, la velocidad es de aproximadamente 30 ms de latencia p99.
Tienda sin conexión: una tienda de solo anexos que le permite realizar un seguimiento de todas las funciones históricas y permitir viajes en el tiempo para evitar la fuga de datos. Los datos se almacenan en formato parquet con partición de tiempo para aumentar la eficiencia de lectura.
Con respecto a la coherencia de las funciones, siempre que el grupo de funciones esté configurado para uso tanto en línea como fuera de línea, los datos se copiarán automática e internamente en la tienda fuera de línea mientras la tienda en línea ingiere la función.
¿Cómo utilizamos la tienda de funciones?

El código que se muestra arriba esconde mucha complejidad. Las tiendas de características nos permiten importar simplemente la interfaz de Python para el entrenamiento y la inferencia del modelo.
Al utilizar el almacén de funciones, nuestros científicos de datos pueden definir funciones fácilmente y crear nuevos modelos sin tener que preocuparse por el tedioso proceso de ingeniería de datos en el backend.
Mejores prácticas para utilizar una tienda de funciones
En nuestra publicación de blog anterior, explicamos cómo usamos una capa de tienda para canalizar funciones hacia la base de datos centralizada. Aquí, nos gustaría compartir dos prácticas recomendadas al utilizar una tienda de funciones:
No ingerimos funciones que no hayan cambiado
Separamos las funciones en dos grupos lógicos: operaciones de usuario activas e inactivas.
Considere este ejemplo. Supongamos que tiene un límite de aceleración de 10K TPS para PutRecord en su tienda de funciones en línea. Utilizando este supuesto, incorporaremos funciones para 100 millones de usuarios. No podemos ingerirlos todos a la vez y, con nuestra velocidad actual, tardará alrededor de 2,7 horas en terminar. Para resolver esto, elegimos incorporar únicamente funciones actualizadas recientemente. Por ejemplo, no incorporaremos una característica si el valor no ha cambiado desde la última vez que se incorporó.
Para el segundo punto, digamos que coloca un conjunto de funciones en un grupo de funciones lógicas. Algunas están activas, mientras que una gran parte está inactiva, lo que significa que la mayoría de las funciones no cambian. El paso lógico, en nuestra opinión, es dividir activos e inactivos en dos grupos de funciones para acelerar el proceso de ingesta.
Para las funciones inactivas, reducimos el 95 % de los datos que necesitamos incorporar al almacén de funciones para 100 millones de usuarios por hora. Además, seguimos reduciendo el 20 % de los datos necesarios para las funciones activas. Entonces, en lugar de tres horas, el proceso de ingesta por lotes procesa funciones por valor de 100 millones de usuarios en 10 minutos.
Pensamientos finales
En resumen, los almacenes de funciones nos permiten reutilizar funciones, acelerar la ingeniería de funciones y minimizar las predicciones inexactas, manteniendo al mismo tiempo la coherencia entre el entrenamiento y la inferencia.
¿Está interesado en utilizar el aprendizaje automático para salvaguardar el ecosistema criptográfico más grande del mundo y a sus usuarios? Consulte Binance Engineering/AI en nuestra página de carreras para conocer las ofertas de trabajo abiertas.
Otras lecturas:
(Blog) Uso de MLOps para crear un canal de aprendizaje automático de un extremo a otro en tiempo real






