
Delivering accurate, consistent, and production-ready machine learning features.

This piece explores our machine learning (ML) feature store in more detail. It’s a continuation of our previous blog post that provides a broader overview of the entire ML pipeline infrastructure.
Why Do We Use a Feature Store?
The feature store, one of the many parts in our pipeline, is arguably the most important cog in the system. Its primary purpose is to function as a central database that manages features before they are shipped off for model training or inference.
If you aren’t familiar with the term, features are essentially raw data that is refined, through a process called feature engineering, into something more usable that our ML models can use to train themselves or calculate predictions.
In a nutshell, feature stores allow us to:
Reuse and share features across different models and teams
Shorten the time required for ML experiments
Minimize inaccurate predictions due to severe training-serving skew
To better understand the importance of a feature store, here’s a diagram of an ML pipeline that doesn’t use one.
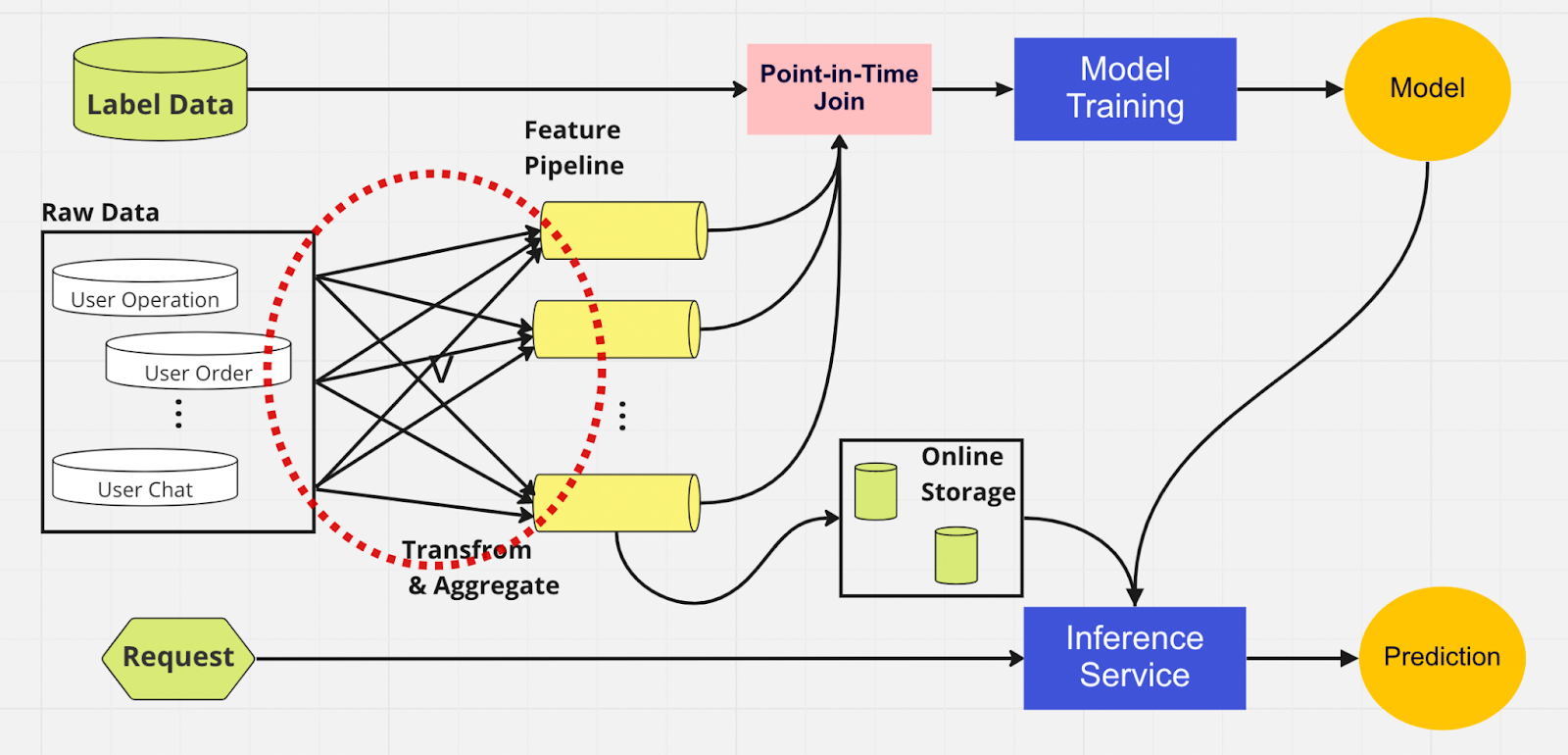
In this pipeline, the two parts — model training and inference service — are unable to identify which features already exist and can be reused. This leads to the ML pipeline duplicating the feature engineering process. You’ll notice in the red circle on the diagram that the ML pipeline, instead of reusing features, has built a clump of duplicate features and redundant pipelines. We call this clump a feature pipeline sprawl.
Maintaining this sprawl of features becomes an increasingly expensive and unmanageable scenario as the business grows and more users enter the platform. Think about it this way; the data scientist must start the feature engineering process, which is long and tedious, entirely from scratch for each new model they create.
Additionally, too much reimplementation of feature logic introduces a concept called training-serving skew, which is a discrepancy between data during the training and inference stage. It leads to inaccurate predictions and unpredictable model behavior that is hard to troubleshoot during production. Before feature stores, our data scientists would check for feature consistency using sanity checks. This is a manual, time-consuming process that diverts attention from higher-priority tasks such as modeling and insightful feature engineering. Now, let’s explore an ML pipeline with a feature store.

Similar to the other pipeline, we have the same data sources and features on the left side. However, instead of going through multiple feature pipelines, we have the feature store as one central hub that serves both phases of the ML pipeline (model training and inference service). There are no duplicate features; all the processes required to build a feature, including transformation and aggregation, only need to be performed once.
Data scientists can intuitively interact with the feature store using our custom-built Python SDK to search, reuse, and discover features for downstream ML model training and inference.
Essentially, the feature store is a centralized database that unifies both phases. And since the feature store guarantees consistent features for training and inference, we can reduce training-serving skew by a significant amount.
Note that feature stores do much more than the points we mentioned above. This is, of course, a more rudimentary summary of why we use a feature store and one that we can further break down into just a few words: prep and send features into ML models in the fastest, easiest way possible.
Inside the Feature Store

The figure above shows your typical feature store layout, be it AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio, or Tetcom. All feature stores provide two types of storage: online or offline.
Online feature stores are used for real-time inference, while offline feature stores are used for batch prediction and model training. Due to the different use cases, the metric we use to evaluate performance is entirely different. In an online feature, we look for low latency. For offline feature stores, we want high throughput.
Developers can choose any enterprise feature store or even open source based on the tech stack. The diagram below outlines key differences between the online and offline stores in the AWS SageMaker Feature Store.

Online store: Stores the most recent copy of features and serves them with low millisecond latency, the speed of which depends on your payload size. For our account takeover (ATO) model, which has eight feature groups and 55 features in total, the speed is around 30 ms p99 latency.
Offline store: An append-only store that allows you to track all historical features and enable time travel to avoid data leakage. Data is stored in parquet format with time-partitioning to increase read efficiency.
Regarding feature consistency, as long as the feature group is configured for both online and offline usage, the data will be automatically and internally copied to the offline store while the feature is ingested by the online store.
How Do We Use the Feature Store?

The code pictured above hides a lot of complexity. Features stores allow us to simply import the python interface for model training and inference.
Using the feature store, our data scientists can easily define features and build new models without having to worry about the tedious data engineering process in the backend.
Best Practices for Using a Feature Store
In our previous blog post, we explained how we use a store layer to funnel features into the centralized DB. Here, we’d like to share two best practices when using a feature store:
We don’t ingest features that haven’t changed
We separate features into two logical groups: active user operations and inactive
Consider this example. Let’s say you have a 10K TPS throttling limit for PutRecord on your online feature store. Using this hypothetical, we’ll ingest features for 100 million users. We can’t ingest them all at once, and with our current speed, it’ll take around 2.7 hours to finish. To solve this, we choose only to ingest recently updated features. For example, we won’t ingest a feature if the value has not changed since the last time it was ingested.
For the second point, let’s say you put a set of features in one logical feature group. Some are active, while a large portion is inactive, meaning most of the features are unchanged. The logical step, in our opinion, is to divide active and inactive into two feature groups to expedite the ingestion process.
For inactive features, we reduce 95% of the data we need to ingest into the feature store for 100 million users on an hourly basis feature pipeline. Plus, we still reduce 20% of the data required for active features. So, instead of three hours, the batch ingestion pipeline processes 100 million users' worth of features in 10 minutes.
Closing Thoughts
To summarize, feature stores allow us to reuse features, expedite feature engineering, and minimize inaccurate predictions — all the while maintaining consistency between training and inference.
Interested in using ML to safeguard the world's largest crypto ecosystem and its users? Check out Binance Engineering/AI on our careers page for open job postings.
Further reading:





