
Poskytování přesných, konzistentních a produkčně připravených funkcí strojového učení.

Tento článek podrobněji zkoumá náš obchod s funkcemi strojového učení (ML). Je to pokračování našeho předchozího blogového příspěvku, který poskytuje širší přehled o celé infrastruktuře potrubí ML.
Proč používáme značkový obchod?
Obchod funkcí, jedna z mnoha částí v našem potrubí, je pravděpodobně nejdůležitějším kolečkem v systému. Jeho primárním účelem je fungovat jako centrální databáze, která spravuje funkce před tím, než jsou odeslány pro trénování modelů nebo odvození.
Pokud tento termín neznáte, funkce jsou v podstatě nezpracovaná data, která se zpřesňují procesem nazývaným inženýrství funkcí na něco použitelnějšího, co naše modely ML mohou použít k trénování nebo k výpočtu předpovědí.
Stručně řečeno, obchody s funkcemi nám umožňují:
Znovu používejte a sdílejte funkce napříč různými modely a týmy
Zkraťte čas potřebný pro ML experimenty
Minimalizujte nepřesné předpovědi kvůli vážnému zkreslení v podávání tréninků
Abyste lépe porozuměli důležitosti obchodu s funkcemi, zde je schéma kanálu ML, který žádný nepoužívá.
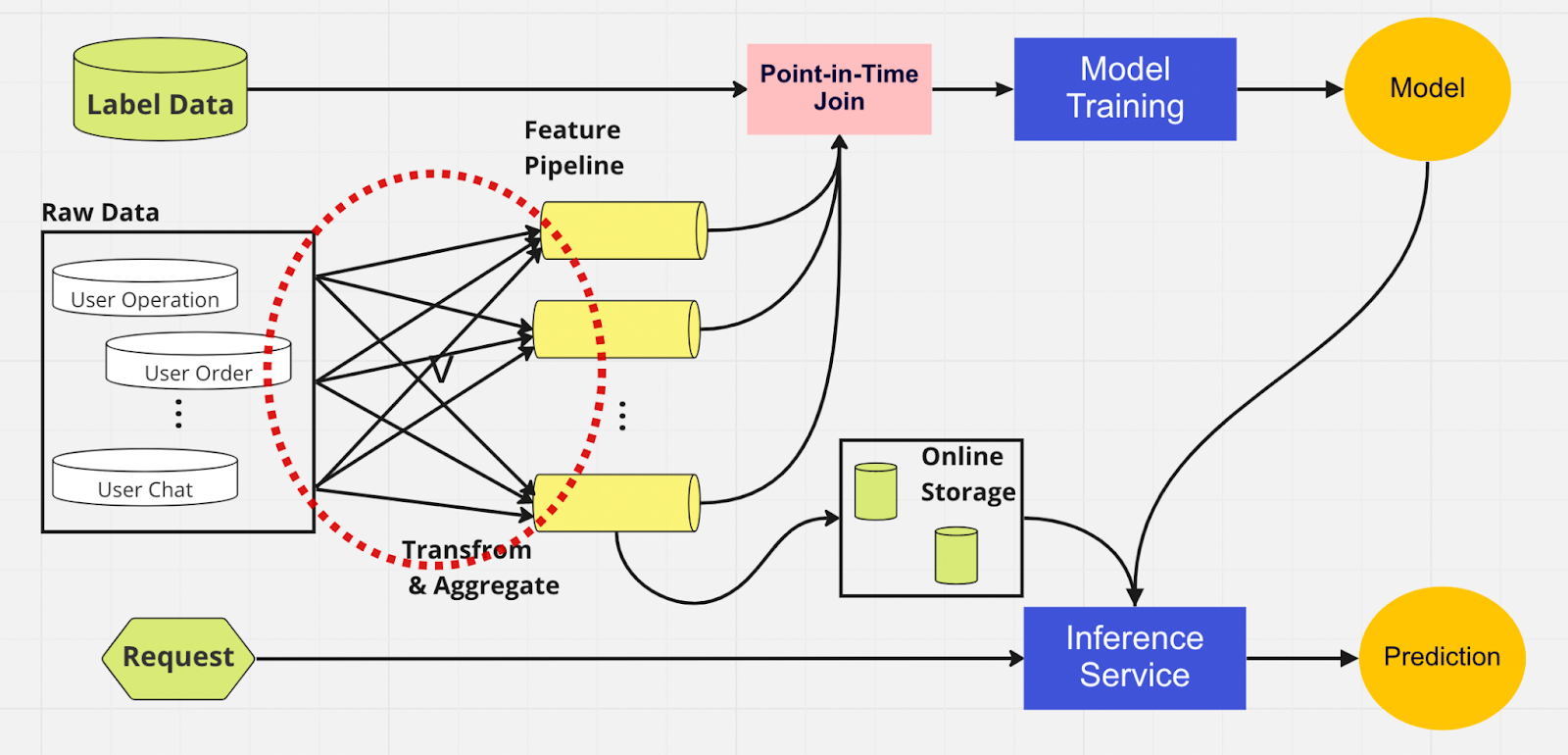
V tomto kanálu nejsou dvě části – modelové školení a inferenční služba – schopny identifikovat, které funkce již existují a lze je znovu použít. To vede k tomu, že kanál ML duplikuje proces inženýrství funkcí. V červeném kruhu na diagramu si všimnete, že kanál ML namísto opětovného použití funkcí vytvořil shluk duplicitních funkcí a nadbytečných kanálů. Tomuto shluku říkáme rozrůstání potrubí funkcí.
Udržování tohoto množství funkcí se stává stále nákladnějším a nezvládnutelným scénářem, protože podnikání roste a na platformu vstupuje více uživatelů. Přemýšlejte o tom takto; datový vědec musí zahájit proces inženýrství funkcí, který je dlouhý a únavný, zcela od nuly pro každý nový model, který vytvoří.
Přílišná reimplementace logiky funkcí navíc zavádí koncept zvaný zešikmení při poskytování školení, což je nesrovnalost mezi daty během trénovací a inferenční fáze. Vede to k nepřesným předpovědím a nepředvídatelnému chování modelu, které se během výroby obtížně řeší. Před uložením funkcí by naši datoví vědci zkontrolovali konzistenci funkcí pomocí kontrol zdravého rozumu. Jedná se o manuální, časově náročný proces, který odvádí pozornost od úkolů s vyšší prioritou, jako je modelování a důmyslné inženýrství funkcí. Nyní prozkoumáme kanál ML s úložištěm funkcí.

Podobně jako u jiného kanálu máme na levé straně stejné zdroje dat a funkce. Místo toho, abychom procházeli několika kanály funkcí, máme úložiště funkcí jako jeden centrální rozbočovač, který slouží oběma fázím kanálu ML (trénink modelů a služba odvození). Neexistují žádné duplicitní funkce; všechny procesy potřebné k vytvoření prvku, včetně transformace a agregace, stačí provést pouze jednou.
Datoví vědci mohou intuitivně komunikovat s úložištěm funkcí pomocí naší vlastní sady Python SDK a vyhledávat, znovu používat a objevovat funkce pro nácvik a vyvozování modelu ML.
Úložiště funkcí je v podstatě centralizovaná databáze, která sjednocuje obě fáze. A protože úložiště funkcí zaručuje konzistentní funkce pro školení a vyvozování, můžeme výrazně snížit zkreslení poskytování školení.
Všimněte si, že obchody s funkcemi umí mnohem více než body, které jsme zmínili výše. Toto je samozřejmě základní shrnutí toho, proč používáme obchod s funkcemi a které můžeme dále rozdělit do několika slov: připravit a odeslat funkce do modelů ML tím nejrychlejším a nejjednodušším možným způsobem.
Uvnitř obchodu s funkcemi

Obrázek výše ukazuje vaše typické rozložení obchodu s funkcemi, ať už je to AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio nebo Tetcom. Všechny obchody s funkcemi poskytují dva typy úložiště: online nebo offline.
Online obchody funkcí se používají pro odvození v reálném čase, zatímco offline obchody funkcí se používají pro dávkovou predikci a trénování modelů. Vzhledem k různým případům použití je metrika, kterou používáme k hodnocení výkonu, zcela odlišná. V online funkci hledáme nízkou latenci. U offline obchodů s funkcemi chceme vysokou propustnost.
Vývojáři si mohou vybrat jakýkoli podnikový obchod s funkcemi nebo dokonce open source na základě technologického balíčku. Níže uvedený diagram nastiňuje klíčové rozdíly mezi online a offline obchody v obchodě funkcí AWS SageMaker.

Internetový obchod: Ukládá nejnovější kopii funkcí a poskytuje je s nízkou milisekundovou latencí, jejíž rychlost závisí na velikosti vašeho užitečného zatížení. U našeho modelu převzetí účtu (ATO), který má osm skupin funkcí a celkem 55 funkcí, se rychlost pohybuje kolem 30 ms p99 latence.
Offline obchod: Obchod pouze pro připojení, který umožňuje sledovat všechny historické funkce a umožňuje cestování v čase, aby se zabránilo úniku dat. Data jsou uložena ve formátu parket s časovým rozdělením pro zvýšení efektivity čtení.
Pokud jde o konzistenci funkcí, pokud je skupina funkcí nakonfigurována pro použití online i offline, data budou automaticky a interně zkopírována do offline obchodu, zatímco je funkce zpracována online obchodem.
Jak používáme obchod s funkcemi?

Kód na obrázku výše skrývá spoustu složitosti. Obchody s funkcemi nám umožňují jednoduše importovat rozhraní pythonu pro modelování a vyvozování.
Pomocí úložiště funkcí mohou naši datoví vědci snadno definovat funkce a vytvářet nové modely, aniž by se museli starat o zdlouhavý proces datového inženýrství v backendu.
Doporučené postupy pro používání obchodu s funkcemi
V našem předchozím příspěvku na blogu jsme vysvětlili, jak používáme vrstvu obchodu k nasměrování funkcí do centralizované databáze. Zde bychom se rádi podělili o dva osvědčené postupy při používání obchodu s funkcemi:
Nepřijímáme funkce, které se nezměnily
Funkce rozdělujeme do dvou logických skupin: aktivní uživatelské operace a neaktivní
Zvažte tento příklad. Řekněme, že máte ve svém online obchodě s funkcemi limit 10K TPS pro PutRecord. Pomocí této hypotézy zpracujeme funkce pro 100 milionů uživatelů. Nemůžeme je zpracovat všechny najednou a při naší současné rychlosti to bude trvat asi 2,7 hodiny. Abychom to vyřešili, rozhodli jsme se přijímat pouze nedávno aktualizované funkce. Objekt například nezpracujeme, pokud se hodnota od posledního zpracování nezměnila.
Za druhý bod řekněme, že vložíte sadu funkcí do jedné logické skupiny funkcí. Některé jsou aktivní, zatímco velká část je neaktivní, což znamená, že většina funkcí je nezměněna. Logickým krokem podle našeho názoru je rozdělit aktivní a neaktivní do dvou skupin funkcí, aby se proces příjmu urychlil.
U neaktivních funkcí snižujeme 95 % dat, která potřebujeme zpracovat do úložiště funkcí pro 100 milionů uživatelů každou hodinu. Navíc stále snižujeme 20 % dat potřebných pro aktivní funkce. Namísto tří hodin tedy dávkový kanál zpracovává 100 milionů funkcí uživatelů za 10 minut.
Závěrečné myšlenky
Abychom to shrnuli, obchody funkcí nám umožňují znovu používat funkce, urychlit konstrukci funkcí a minimalizovat nepřesné předpovědi – to vše při zachování konzistence mezi školením a dedukcí.
Zajímá vás používání ML k ochraně největšího světového krypto ekosystému a jeho uživatelů? Podívejte se na Binance Engineering/AI na naší kariérní stránce pro otevřené nabídky práce.
Další čtení:
(Blog) Využití MLOps k vytvoření kompletního kanálu strojového učení v reálném čase