Đảm bảo độ tin cậy và khả năng mở rộng tại Binance: Vai trò của hoạt động quản lý công suất và thử nghiệm tải tự động
Các nội dung chính
Binance thúc đẩy khả năng quản lý công suất cho các đợt tăng lưu lượng truy cập ngoài dự kiến do tình hình biến động mạnh, đảm bảo cơ sở hạ tầng và tài nguyên máy tính đầy đủ, kịp thời cho nhu cầu giao dịch.
Binance thử nghiệm khả năng xử lý theo khối lượng trong môi trường thực tế (chứ không phải môi trường thử nghiệm) để thu được chuẩn dịch vụ chính xác. Phương pháp này giúp xác thực rằng việc phân bổ tài nguyên của chúng tôi là đủ để phục vụ công việc tải đã xác định.
Cơ sở hạ tầng của Binance phải xử lý lượng lớn lưu lượng truy cập và việc duy trì dịch vụ mà người dùng có thể nương cậy yêu cầu khả năng quản lý công suất và thử nghiệm khả năng xử lý theo khối lượng tự động phù hợp.

Tại sao Binance cần một quy trình quản lý công suất chuyên biệt?
Quản lý công suất là nền tảng của sự ổn định của hệ thống. Hoạt động này đòi hỏi các tài nguyên cơ sở hạ tầng và ứng dụng có quy mô phù hợp với nhu cầu giao dịch hiện tại cũng như tương lai với chi phí phù hợp. Nhằm góp phần đạt được mục tiêu này, chúng tôi xây dựng các công cụ và quy trình quản lý công suất để tránh tình trạng quá tải, đồng thời giúp các doanh nghiệp cung cấp trải nghiệm mượt mà cho người dùng.
Thị trường tiền mã hóa thường trải qua các giai đoạn biến động thường xuyên hơn so với thị trường tài chính truyền thống. Điều này nghĩa là hệ thống của Binance thỉnh thoảng sẽ phải chịu lưu lượng truy cập tăng đột biến này khi người dùng phản ứng với các biến động của thị trường. Bằng cách quản lý công suất phù hợp, chúng tôi luôn duy trì đủ công suất cho nhu cầu giao dịch chung và các tình huống lưu lượng truy cập tăng đột biến này. Đây chính là điểm mấu chốt giúp các quy trình quản lý công suất của Binance trở nên độc đáo và đầy thách thức.
Hãy xem xét các yếu tố thường cản trở quy trình và dẫn đến dịch vụ chậm hoặc không hoạt động. Đầu tiên, chúng ta gặp phải tình trạng quá tải, thường là do lưu lượng truy cập tăng đột ngột. Ví dụ: tình trạng này có thể là kết quả của một sự kiện tiếp thị, thông báo đẩy hoặc thậm chí là một cuộc tấn công DDoS (từ chối dịch vụ phân tán).
Việc lưu lượng truy cập tăng và công suất không đủ ảnh hưởng đến chức năng hệ thống như sau:
Dịch vụ đảm nhận ngày càng nhiều công việc.
Thời gian phản hồi tăng đến mức không có yêu cầu nào có thể được phản hồi trong khoảng thời gian chờ của máy khách. Sự xuống cấp này thường xảy ra do tình trạng bão hòa tài nguyên (CPU, bộ nhớ, IO, mạng lưới, v.v.) hoặc tạm dừng GC kéo dài trong chính dịch vụ hoặc các thành phần phụ thuộc của dịch vụ.
Kết quả là dịch vụ sẽ không thể xử lý các yêu cầu kịp thời.
Làm hỏng quá trình
Chúng ta đã thảo luận về nguyên tắc chung của quản lý công suất, giờ hãy xem cách Binance áp dụng điều này vào hoạt động giao dịch của mình. Dưới đây là tổng quan kiến trúc cho hệ thống quản lý công suất của chúng tôi cùng một số quy trình công việc chính.
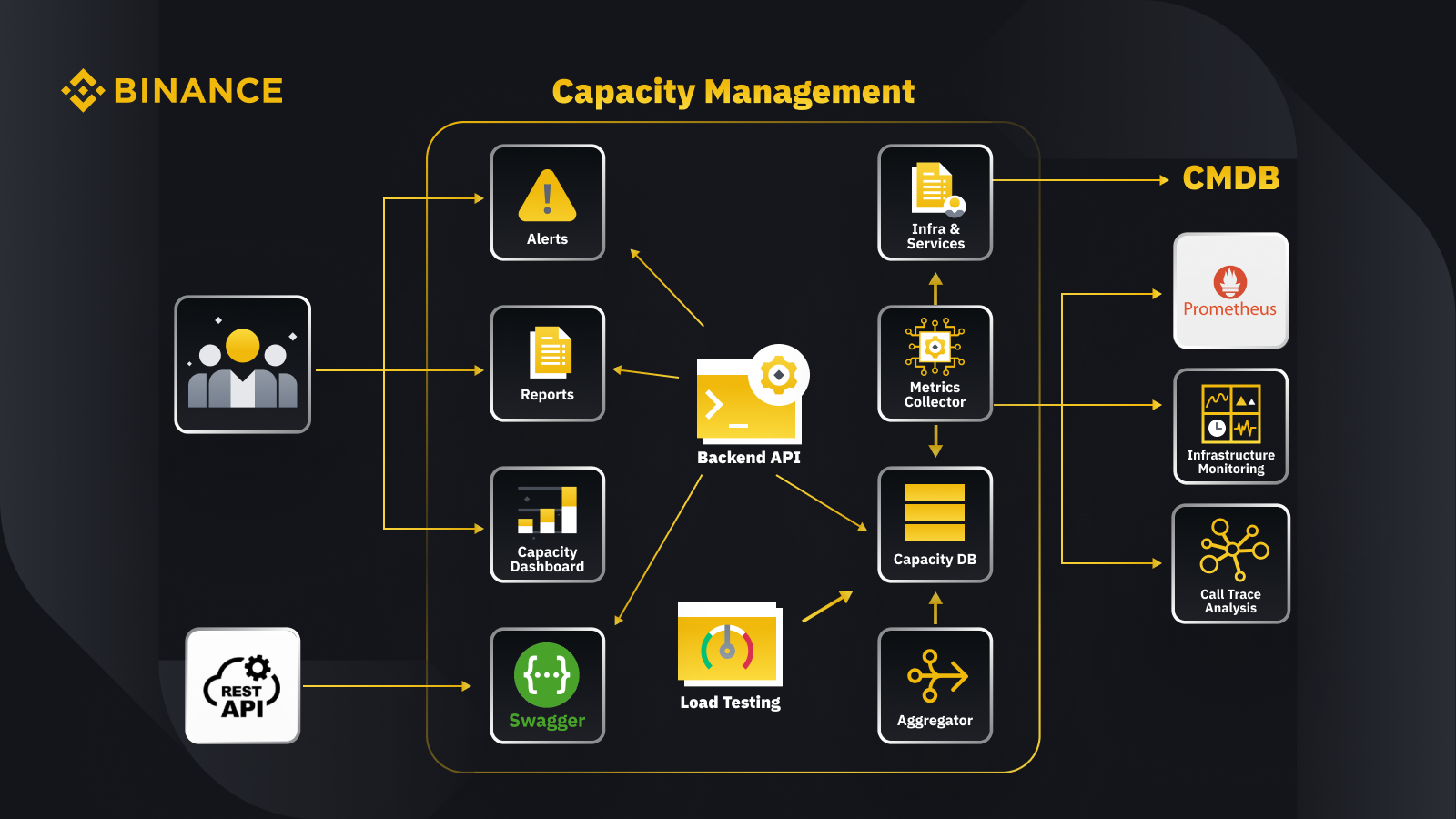
Bằng cách tìm nạp dữ liệu từ cơ sở dữ liệu quản lý cấu hình (CMDB), chúng tôi tạo cấu hình cơ sở hạ tầng và dịch vụ. Các mục trong các cấu hình này là các đối tượng quản lý công suất.
Trình thu thập số liệu tìm nạp các số liệu công suất từ Prometheus cho dữ liệu lớp dịch vụ và doanh nghiệp, Giám sát cơ sở hạ tầng cho các số liệu lớp tài nguyên và hệ thống phân tích theo dõi lệnh gọi để biết thông tin theo dõi. Trình thu thập số liệu lưu trữ dữ liệu trong cơ sở dữ liệu công suất (CDB).
Hệ thống thử nghiệm khả năng xử lý theo khối lượng là quá trình thực hiện các đợt thử nghiệm nghiêm ngặt trên các dịch vụ và lưu trữ dữ liệu tiêu chuẩn trong CDB.
Trình tổng hợp lấy dữ liệu công suất từ CDB rồi tổng hợp dữ liệu đó cho các thứ nguyên hàng ngày và all-time high (ATH). Sau khi tổng hợp, trình này ghi dữ liệu đã tổng hợp trở lại vào CDB.
Bằng cách xử lý dữ liệu từ CDB, API phụ trợ cung cấp các giao diện cho bảng điều khiển công suất, cảnh báo và báo cáo, cũng như API còn lại và dữ liệu công suất liên quan để tích hợp.
Các bên liên quan nhận được thông tin chuyên sâu về công suất thông qua bảng điều khiển công suất, cảnh báo và báo cáo. Họ cũng có thể sử dụng các hệ thống liên quan khác, bao gồm việc giám sát nhận dữ liệu công suất của dịch vụ với API còn lại do hệ thống quản lý công suất với Swagger cung cấp.
Chiến lược
Chiến lược lập kế hoạch và quản lý công suất của chúng tôi dựa trên quy trình xử lý theo định hướng cao điểm. Quy trình xử lý theo định hướng cao điểm là khối lượng công việc mà tài nguyên của dịch vụ (máy chủ web, cơ sở dữ liệu, v.v.) phải trải qua trong thời gian sử dụng cao điểm.
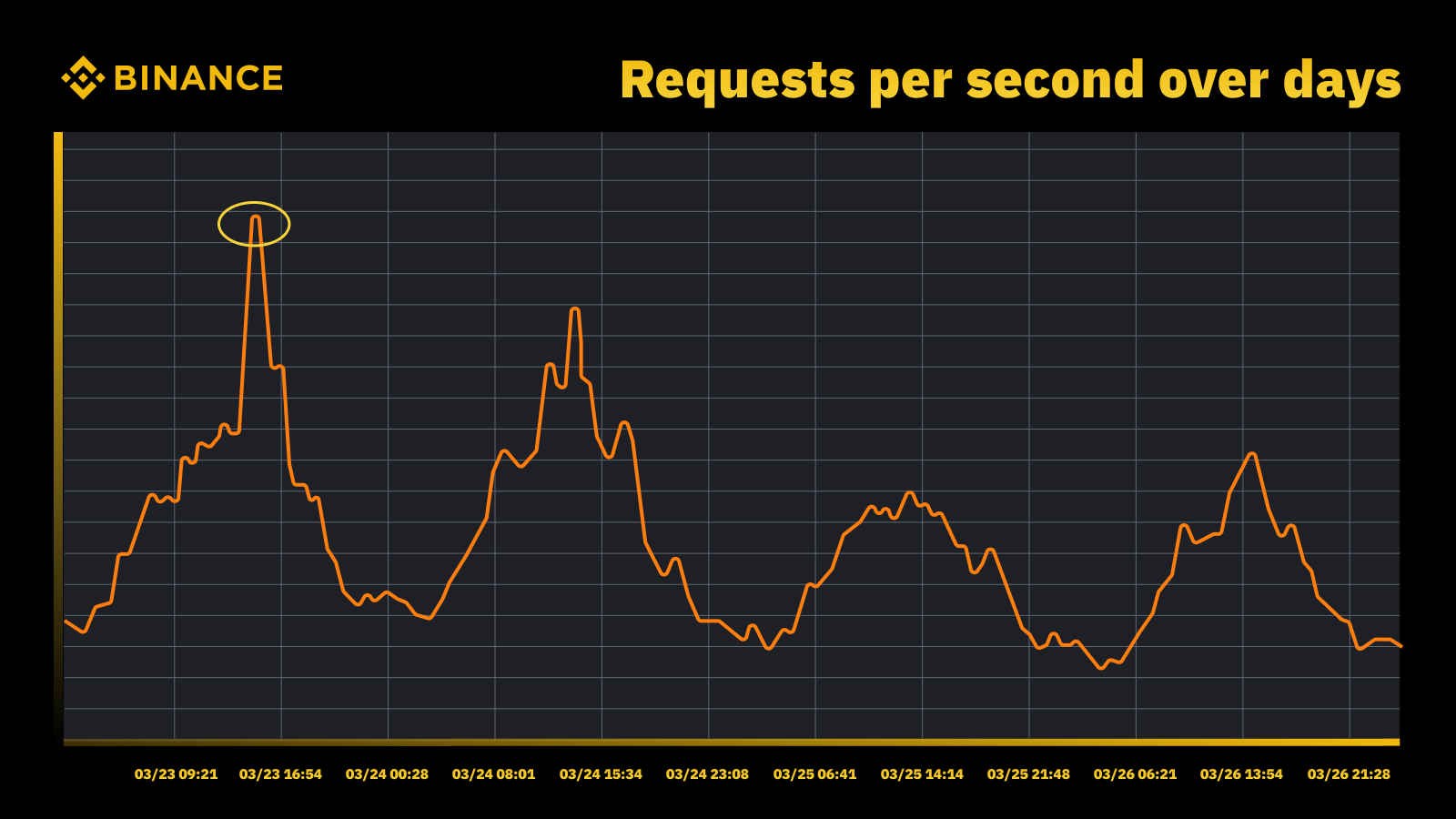
Lượng truy cập tăng đột biến khi Fed tăng lãi suất vào tháng 3 năm 2023
Chúng tôi phân tích các đỉnh định kỳ và sử dụng dữ liệu này để định hướng quỹ đạo công suất. Như với bất kỳ nguồn lực theo định hướng cao điểm nào, chúng tôi muốn tìm hiểu thời điểm các đỉnh xảy ra, rồi khám phá vấn đề đang thực sự diễn ra trong các chu kỳ đó.
Một điều quan trọng khác mà chúng tôi xem xét cùng với việc ngăn chặn tình trạng quá tải là chức năng tự động thay đổi quy mô. Chức năng Tự động thay đổi quy mô xử lý tình trạng quá tải bằng cách tự động tăng công suất với nhiều phiên bản dịch vụ hơn. Sau đó, lưu lượng vượt quá sẽ được phân phối, đồng thời lưu lượng mà một phiên bản duy nhất của dịch vụ (hoặc phần phụ thuộc) xử lý vẫn quản lý được.
Tự động thay đổi quy mô hữu ích nhưng lại thiếu khả năng xử lý các tình huống quá tải. Chức năng thường không thể phản ứng đủ nhanh với lưu lượng truy cập tăng đột ngột và chỉ hoạt động hiệu quả nhất khi lưu lượng gia tăng dần dần.
Đo lường
Đo lường đóng một vai trò quan trọng trong công việc quản lý công suất của Binance và thu thập dữ liệu là bước đo lường đầu tiên của chúng tôi. Dựa trên các tiêu chuẩn Thư viện cơ sở hạ tầng công nghệ thông tin (ITIL), chúng tôi thu thập dữ liệu để đo lường trong các quy trình phụ quản lý công suất, cụ thể là:
Tài nguyên - Mức tiêu thụ tài nguyên của cơ sở hạ tầng CNTT do việc dùng ứng dụng/dịch vụ. Tập trung vào các chỉ số hiệu suất nội bộ của tài nguyên máy tính vật lý và máy ảo, bao gồm CPU máy chủ, bộ nhớ, lưu trữ đĩa, băng thông mạng, v.v.
Dịch vụ. Các thước đo hiệu suất, SLA, tốc độ xử lý và thông lượng ở cấp ứng dụng phát sinh từ những hoạt động giao dịch. Tập trung vào các chỉ số hiệu suất bên ngoài dựa trên cách người dùng cảm nhận về dịch vụ, bao gồm tốc độ xử lý, thông lượng, khi dịch vụ đạt tối đa công suất, v.v.
Giao dịch. Thu thập dữ liệu đo lường các hoạt động giao dịch do ứng dụng đích xử lý, bao gồm lệnh, đăng ký người dùng, thanh toán, v.v.
Quy trình quản lý công suất chỉ dựa trên việc sử dụng tài nguyên cơ sở hạ tầng sẽ dẫn đến việc lập kế hoạch không chính xác. Bởi vì dữ liệu này có thể không đại diện cho khối lượng giao dịch thực tế và thông lượng thúc đẩy công suất cơ sở hạ tầng của chúng tôi.
Các sự kiện theo lịch trình cung cấp một nơi tuyệt vời để thảo luận thêm về vấn đề này. Tham gia Watch Web Summit 2022 trên Binance Live để cùng chia sẻ số tiền lên tới 15.000 BUSD trong chương trình Phần thưởng hộp tiền mã hóa . Ngoài các chỉ số lớp dịch vụ và tài nguyên cơ bản, chúng tôi cũng cần xem xét khối lượng giao dịch. Chúng tôi lập kế hoạch công suất ở đây dựa trên các số liệu giao dịch như số lượng người xem phát trực tiếp ước tính, yêu cầu số người tham gia tối đa để nhận Crypto Box, tốc độ xử lý từ đầu đến cuối cùng nhiều yếu tố khác.
Sau khi thu thập dữ liệu, các quy trình quản lý công suất của chúng tôi sẽ tổng hợp và tóm tắt nhiều điểm dữ liệu được thu thập dựa trên trình điều khiển công suất cụ thể. Giá trị tổng hợp của một số liệu là giá trị duy nhất có thể dùng trong hoạt động cảnh báo, báo cáo công suất và các chức năng khác liên quan đến công suất.
Chúng tôi có thể áp dụng một số phương pháp tổng hợp dữ liệu cho các điểm dữ liệu định kỳ, như tổng, trung bình, trung vị, tối thiểu, tối đa, phân vị và all-time-high (ATH).

Phương pháp chúng tôi đã chọn giúp xác định kết quả đầu ra ngay từ quy trình quản lý công suất và các quyết định tương ứng. Chúng tôi lựa chọn nhiều phương pháp dựa trên các kịch bản khác nhau. Ví dụ: Chúng tôi sử dụng phương pháp tối đa cho các dịch vụ quan trọng và các điểm dữ liệu liên quan. Để ghi lại lưu lượng truy cập cao nhất, chúng tôi sử dụng phương pháp ATH.
Đối với nhiều trường hợp sử dụng, chúng tôi sử dụng các loại mức độ chi tiết khác nhau để tổng hợp dữ liệu. Trong hầu hết các trường hợp, chúng tôi sử dụng phút, giờ, ngày hoặc ATH.
Với độ chi tiết từng phút, chúng tôi đo lường khối lượng công việc của dịch vụ để cảnh báo tình trạng quá tải kịp thời.
Chúng tôi sử dụng dữ liệu tổng hợp hàng giờ để xây dựng dữ liệu hàng ngày và tổng hợp dữ liệu hàng giờ để ghi lại mức cao nhất hàng ngày.
Thông thường, chúng tôi sử dụng dữ liệu hàng ngày cho báo cáo công suất, đồng thời tận dụng dữ liệu ATH để lập mô hình và lập kế hoạch công suất.
Một trong những số liệu cốt lõi của việc quản lý công suất là tiêu chuẩn dịch vụ. Nhờ đó, chúng tôi có thể đo lường chính xác hiệu suất và công suất của dịch vụ. Chúng tôi đạt đáp ứng tiêu chuẩn dịch vụ bằng cách thử nghiệm tải và chúng tôi sẽ đi sâu hơn về vấn đề này sau.
Quản lý công suất dựa trên mức độ ưu tiên
Tính đến nay, chúng tôi đã ghi nhận cách nền tảng thu thập chỉ số công suất và tổng hợp dữ liệu theo các loại mức độ chi tiết khác nhau. Một lĩnh vực quan trọng khác cần thảo luận là mức độ ưu tiên, yếu tố rất hữu ích trong bối cảnh báo cáo và cảnh báo công suất. Sau khi xếp hạng tài sản CNTT, việc sử dụng cơ sở hạ tầng bị hạn chế, đồng thời tài nguyên máy tính được ưu tiên và cung cấp cho các dịch vụ cũng như hoạt động quan trọng trước.
Có một số cách để xác định dịch vụ và mức độ quan trọng của yêu cầu. Một địa chỉ tham khảo hữu ích là Google. Trong sách SRE. Những dịch vụ này xác định các mức độ quan trọng là CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS, v.v. Tương tự, chúng tôi xác định nhiều mức độ ưu tiên như P0, P1, P2, v.v.
Chúng tôi xác định các mức độ ưu tiên như sau:
P0: Đối với các dịch vụ và yêu cầu quan trọng nhất, những yêu cầu và dịch vụ đó sẽ dẫn đến tác động nghiêm trọng mà người dùng có thể nhận thấy nếu yêu cầu không diễn ra thành công.
P1: Đối với những dịch vụ và yêu cầu sẽ dẫn đến tác động mà người dùng có thể nhận thấy, nhưng tác động ít hơn so với P0. Các dịch vụ P0 và P1 dự kiến sẽ được cung cấp đủ công suất.
P2: Đây là mức độ ưu tiên mặc định cho công việc hàng loạt và công việc ngoại tuyến. Các dịch vụ và yêu cầu này có thể không dẫn đến tác động mà người dùng có thể nhận thấy trong trường hợp không hoạt động một phần.
Thử nghiệm tải là gì và tại sao chúng ta sử dụng phương thức này trong môi trường sản xuất?
Thử nghiệm tải là một quy trình kiểm tra phần mềm phi chức năng trong đó hiệu suất của ứng dụng được kiểm tra theo một khối lượng công việc cụ thể. Nhờ đó, bạn có thể xác định cách ứng dụng hoạt động trong lúc có nhiều người dùng cuối truy cập đồng thời.
Tại Binance, chúng tôi tạo ra một giải pháp cho phép nền tảng chạy thử nghiệm tải trong sản xuất. Thông thường, quy trình thử nghiệm tải được chạy trong môi trường mô phỏng. Tuy nhiên, chúng tôi không thể sử dụng cách này vì các mục tiêu quản lý công suất tổng thể của mình. Thử nghiệm tải trong môi trường sản xuất cho phép chúng tôi:
Thu thập tiêu chuẩn chính xác cho các dịch vụ trong điều kiện tải thực tế.
Tăng niềm tin vào độ ổn định và hiệu suất của hệ thống.
Xác định các tắc nghẽn trong hệ thống trước khi tình trạng này xảy ra trong môi trường sản xuất.
Cho phép giám sát liên tục môi trường sản xuất.
Cho phép quản lý công suất chủ động với các chu kỳ thử nghiệm được chuẩn hóa diễn ra thường xuyên.
Dưới đây, bạn có thể thấy khung thử nghiệm tải của chúng tôi với một số điểm chính:

Khung vi dịch vụ của Binance có một lớp cơ sở để hỗ trợ định tuyến lưu lượng dựa trên cấu hình và dựa trên cờ. Điều này rất cần thiết cho phương pháp TIP của chúng tôi.
Phân tích canary tự động (ACA) được áp dụng để đánh giá phiên bản mà chúng tôi đang thử nghiệm. Phương pháp này so sánh các số liệu chính được thu thập trong hệ thống giám sát. Vì vậy, chúng tôi có thể tạm dừng/chấm dứt thử nghiệm nếu có bất kỳ sự cố không mong muốn nào xảy ra để giảm thiểu tác động đến người dùng.
Tiêu chuẩn và chỉ số được thu thập trong quá trình thử nghiệm tải để tạo thông tin chi tiết về dữ liệu liên quan đến hành vi và hiệu suất ứng dụng.
Các API dùng để chia sẻ dữ liệu hiệu suất có giá trị trong những tình huống khác nhau, chẳng hạn như quản lý công suất và đảm bảo chất lượng. Điều này giúp xây dựng một hệ sinh thái mở.
Chúng tôi tạo quy trình công việc tự động hóa để sắp xếp tất cả các bước và điểm kiểm soát từ góc độ thử nghiệm toàn diện. Chúng tôi cũng cung cấp khả năng tích hợp linh hoạt với các hệ thống khác, chẳng hạn như đường dẫn CI/CD và cổng thông tin vận hành.
Phương pháp thử nghiệm trong sản xuất (TIP) của chúng tôi
Phương pháp thử nghiệm hiệu suất truyền thống (chạy thử nghiệm trong môi trường mô phỏng với lưu lượng truy cập được mô phỏng hoặc phản chiếu) mang lại một số lợi ích. Tuy nhiên, việc triển khai một môi trường mô phỏng giống sản xuất vẫn có nhiều nhược điểm nếu đặt trong bối cảnh của chúng tôi:
Phương thức này làm tăng gần như gấp đôi chi phí cơ sở hạ tầng và nỗ lực bảo trì.
Việc vận hành toàn diện trong sản xuất là vô cùng phức tạp, đặc biệt là trong môi trường vi dịch vụ quy mô lớn trên nhiều đơn vị kinh doanh.
Quy trình này làm tăng thêm nhiều rủi ro bảo mật và quyền riêng tư dữ liệu vì chắc chắn chúng tôi cần sao chép dữ liệu trong quá trình mô phỏng.
Lưu lượng mô phỏng sẽ không bao giờ sao chép những gì thực sự xảy ra trong quá trình sản xuất. Tiêu chuẩn thu được trong môi trường mô phỏng sẽ không chính xác và có ít giá trị hơn
Thử nghiệm trong sản xuất, còn được gọi là TIP, là một phương pháp thử nghiệm chuyển đổi phù hợp trong đó mã, tính năng và bản phát hành mới được thử nghiệm trong môi trường sản xuất. Phương thức thử nghiệm tải trong sản xuất mà chúng tôi đã áp dụng rất có lợi vì phương thức này giúp chúng tôi:
Phân tích tính ổn định và hiệu quả của hệ thống.
Khám phá tiêu chuẩn và điểm tắc nghẽn của ứng dụng trong tình huống mức lưu lượng truy cập, thông số kỹ thuật máy chủ và thông số ứng dụng khác nhau.
Định tuyến dựa trên FlowFlag
Định tuyến dựa trên FlowFlag được nhúng trong khung cơ sở vi dịch vụ là nền tảng để biến TIP thành hiện thực. Điều này đúng với các trường hợp cụ thể, bao gồm các ứng dụng dùng tính năng khám phá dịch vụ Eureka để phân bổ lưu lượng.
Như được minh họa trong sơ đồ, máy chủ web Binance có vai trò là điểm truy cập sẽ gắn nhãn một số phần trăm lưu lượng truy cập như đã chỉ định trong cấu hình với tiêu đề FlowFlag. Trong quá trình kiểm tra tải, chúng tôi có thể chọn một máy chủ của một dịch vụ cụ thể và đánh dấu làm phiên bản perf đích trong configs. Sau đó, các yêu cầu perf được gắn nhãn đó cuối cùng sẽ được chuyển đến phiên bản perf khi chuyển đến dịch vụ để xử lý.
Hệ thống hoàn toàn dựa trên cấu hình và tải nhanh, chúng tôi có thể dễ dàng điều chỉnh phần trăm khối lượng công việc bằng cách sử dụng quy trình tự động hóa mà không cần phải triển khai bản phát hành mới
Cơ chế này có thể được áp dụng rộng rãi cho hầu hết các dịch vụ của chúng tôi vì đây là một phần của gói cổng và cơ sở
Chỉ có một điểm thay đổi nên dễ dàng hoàn nguyên để giảm thiểu rủi ro trong sản xuất

Trong quá trình chuyển đổi giải pháp sang dịch vụ đám mây, chúng tôi cũng dần khám phá cách nền tảng có thể xây dựng một phương pháp tương tự để hỗ trợ quy trình định tuyến lưu lượng truy cập khác do nhà cung cấp đám mây công cộng hoặc Kubernetes mang đến.
Phân tích canary tự động để giảm thiểu rủi ro tác động của người dùng
Triển khai Canary là một chiến lược triển khai để giảm rủi ro khi triển khai phiên bản phần mềm mới vào sản xuất. Chiến lược này thường liên quan đến việc triển khai một phiên bản mới của phần mềm, được gọi là bản phát hành canary, cho một nhóm nhỏ người dùng cùng với phiên bản đang chạy ổn định. Sau đó, chúng tôi phân chia lưu lượng giữa hai phiên bản để một phần yêu cầu đến được chuyển hướng tới canary.
Chất lượng của phiên bản canary sau đó được đánh giá thông qua phân tích canary. Phân tích này so sánh các chỉ số chính mô tả hành vi của phiên bản cũ và mới. Nếu có sự xuống cấp đáng kể của chỉ số, canary sẽ bị hủy bỏ và tất cả lưu lượng truy cập được chuyển đến phiên bản ổn định để giảm thiểu tác động của hành vi không mong muốn.
Chúng tôi sử dụng cùng một khái niệm để xây dựng giải pháp thử nghiệm tải tự động của mình. Giải pháp sử dụng nền tảng Kayenta để phân tích canary tự động (ACA) thông qua Spinnaker và cho phép triển khai canary tự động. Quy trình thử nghiệm tải điển hình của chúng tôi khi thực hiện theo phương pháp này diễn ra như sau:
Thông qua quy trình làm việc, chúng tôi tăng dần lưu lượng truy cập (ví dụ: 5%, 10%, 25%, 50%) vào máy chủ mục tiêu theo chỉ định hoặc cho đến khi đạt đến điểm giới hạn.
Trong mỗi lần tải, phân tích canary được chạy lặp lại với Kayenta trong một khoảng thời gian (ví dụ: 5 phút) để so sánh các chỉ số chính của máy chủ được thử nghiệm với khoảng thời gian trước khi tải làm cơ sở và khoảng thời gian sau tải hiện tại làm thử nghiệm.
Việc so sánh (mô hình cấu hình canary) tập trung vào việc kiểm tra xem máy chủ đích:
Đạt đến giới hạn tài nguyên, ví dụ: mức sử dụng CPU vượt quá 90%.
Có sự gia tăng đáng kể về chỉ số lỗi, ví dụ: nhật ký lỗi, trường hợp ngoại lệ HTTP hoặc từ chối giới hạn tốc độ.
Có các chỉ số ứng dụng cốt lõi vẫn hợp lý, ví dụ: tốc độ xử lý HTTP dưới 2 giây (có thể tùy chỉnh cho từng dịch vụ)
Đối với mỗi phân tích, Kayenta cung cấp cho chúng tôi một báo cáo để chỉ ra kết quả và thử nghiệm sẽ kết thúc ngay lập tức khi thất bại.
Quá trình phát hiện lỗi này thường mất chưa đến 30 giây, giúp giảm đáng kể khả năng ảnh hưởng đến trải nghiệm của người dùng cuối của chúng tôi.

Kích hoạt thông tin chi tiết về dữ liệu
Điều quan trọng là phải thu thập đầy đủ thông tin về tất cả các quy trình và quá trình thực hiện thử nghiệm được mô tả trước đây. Mục tiêu cuối cùng là cải thiện độ tin cậy và độ bền bỉ của hệ thống, mục tiêu không thể thực hiện nếu không có thông tin chuyên sâu về dữ liệu.
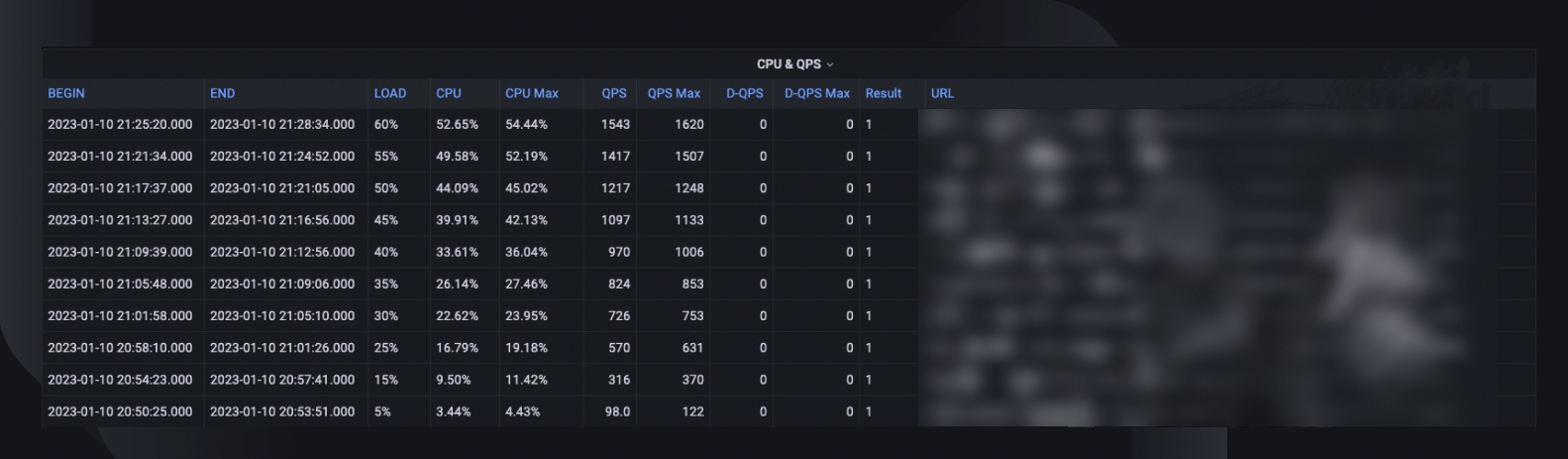
Tóm tắt thử nghiệm tổng thể ghi lại phần trăm tải tối đa mà máy chủ có thể xử lý, mức sử dụng CPU cao nhất và QPS của máy chủ. Dựa vào đó, hệ thống cũng ước tính số lượng phiên bản mà chúng tôi có thể cần triển khai để đáp ứng dự trữ công suất của mình, xem xét QPS all-high-time của dịch vụ.
Thông tin có giá trị khác để phân tích bao gồm phiên bản phần mềm, thông số kỹ thuật của máy chủ, số lượng đã triển khai và liên kết đến bảng điều khiển màn hình nơi chúng tôi có thể xem lại những vấn đề đã xảy ra trong quá trình thử nghiệm.

Đường tiêu chuẩn cho biết hiệu suất đã thay đổi như thế nào trong ba tháng qua để chúng tôi có thể khám phá bất kỳ vấn đề nào có thể xảy ra liên quan đến một bản phát hành ứng dụng cụ thể.

Xu hướng CPU và QPS cho thấy mức độ sử dụng CPU tương quan với khối lượng yêu cầu mà máy chủ phải xử lý. Số liệu này có thể giúp ước tính khoảng không của máy chủ để tăng lưu lượng truy cập đến.
Hành vi tốc độ xử lý của API nắm bắt sự thay đổi đối với thời gian phản hồi trong các điều kiện tải khác nhau của năm API hàng đầu. Sau đó, chúng tôi có thể tối ưu hóa hệ thống nếu cần ở cấp API riêng lẻ.

Chỉ số phân bổ tải API giúp chúng tôi hiểu cách thành phần API tác động đến hiệu suất dịch vụ và cung cấp thêm thông tin chi tiết về các lĩnh vực cải tiến.
Bình thường hóa và sản xuất
Khi hệ thống của chúng tôi ngày càng phát triển và đi lên, chúng tôi sẽ tiếp tục theo dõi và cải thiện độ ổn định cũng như độ tin cậy của dịch vụ. Chúng tôi sẽ tiếp tục thực hiện mục tiêu này thông qua:
Một lịch trình thử nghiệm tải thường xuyên và được thiết lập cho các dịch vụ quan trọng.
Thử nghiệm tải tự động như một phần trong quy trình CI/CD của chúng tôi.
Tăng cường xây dựng giải pháp toàn diện để chuẩn bị cho việc áp dụng quy mô lớn trên toàn tổ chức rộng lớn hơn.
Các hạn chế
Có một số hạn chế đối với phương pháp thử nghiệm tải hiện tại:
Định tuyến dựa trên FlowFlag chỉ áp dụng cho khung vi dịch vụ của chúng tôi. Chúng tôi đang tìm cách mở rộng giải pháp cho nhiều tình huống định tuyến hơn bằng cách tận dụng tính năng định tuyến có trọng số phổ biến của trình cân bằng tải trên đám mây hoặc Kubernetes Ingress.
Vì chúng tôi kiểm tra dựa trên lưu lượng truy cập thực của người dùng trong sản xuất nên chúng tôi không thể thực hiện kiểm tra tính năng đối với các API hoặc trường hợp sử dụng cụ thể. Ngoài ra, đối với các dịch vụ có khối lượng rất thấp, giá trị sẽ bị giới hạn vì chúng tôi có thể không xác định được nút thắt của vấn đề.
Chúng tôi thực hiện các thử nghiệm này đối với các dịch vụ riêng lẻ thay vì đưa vào các chuỗi cuộc gọi toàn diện.
Thử nghiệm trong sản xuất đôi khi có thể ảnh hưởng đến người dùng thực nếu xảy ra lỗi. Do đó chúng ta phải có phân tích lỗi và tự động khôi phục khả năng tự động hóa hoàn toàn.
Tổng kết
Điều quan trọng đối với chúng tôi là nghĩ về các tình huống lưu lượng truy cập tăng đột biến để ngăn chặn tình trạng quá tải hệ thống và đảm bảo thời gian hoạt động. Đó là lý do tại sao chúng tôi đã xây dựng các quy trình thử nghiệm tải và quản lý công suất như mô tả trong suốt bài viết này. Tóm lại:
Hệ thống quản lý công suất của chúng tôi theo định hướng cao điểm và được nhúng trong mọi giai đoạn vòng đời dịch vụ, ngăn chặn tình trạng quá tải với các hoạt động như đo lường, thiết lập mức độ ưu tiên, cảnh báo và báo cáo công suất, v.v. Cuối cùng, đây là điều làm cho các quy trình và nhu cầu của Binance trở nên khác biệt so với tình huống quản lý công suất thông thường.
Tiêu chuẩn dịch vụ thu được từ thử nghiệm tải là đầu mối quản lý và lập kế hoạch công suất. Tiêu chuẩn này xác định chính xác tài nguyên cơ sở hạ tầng cần thiết để hỗ trợ nhu cầu giao dịch ở hiện tại và trong tương lai. Cuối cùng, tiêu chuẩn phải được áp dụng trong quá trình sản xuất bằng một giải pháp độc đáo do Binance xây dựng. Nhờ đó, chúng tôi có thể đáp ứng các nhu cầu cụ thể.
Với tất cả những điều được tổng hợp lại, chúng tôi hy vọng bạn có thể thấy rằng việc lập kế hoạch tốt và khuôn khổ kỹ lưỡng sẽ giúp tạo ra dịch vụ mà các Binancian biết đến và yêu thích.
Đọc thêm
(Blog) Cách Binance Ledger tối ưu trải nghiệm của bạn với Binance
(Blog) Giới thiệu Binance Oracle VRF: Thế hệ tiếp theo của tính ngẫu nhiên có thể kiểm chứng
(Blog) Binance tham gia Liên minh FIDO để chuẩn bị triển khai khóa truy cập
Nội dung tham chiếu
[1] Dominic Ogbonna, A-Z of Capacity Management: Practical Guide for Implementing Enterprise IT Monitoring & Capacity Planning, Chapter 4, Chapter 6: https://www.amazon.com/Capacity-Management-Implementing-Enterprise-Monitoring-ebook/dp/B07871VCFR
[2] Luis Quesada Torres, Doug Colish, SRE Best Practices for Capacity Management: https://static.googleusercontent.com/media/sre.google/en//static/pdf/login_winter20_10_torres.pdf
[3] Alejandro Forero Cuervo, Sarah Chavis, Google SRE book, Chapter 21 - Handling Overload: https://sre.google/sre-book/handling-overload