
Предоставление точных, последовательных и готовых к использованию функций машинного обучения.

В этой статье более подробно рассматривается наш магазин функций машинного обучения (ML). Это продолжение нашей предыдущей статьи в блоге, в которой представлен более широкий обзор всей инфраструктуры конвейера машинного обучения.
Почему мы используем хранилище функций?
Хранилище функций, одна из многих частей нашего конвейера, возможно, является самым важным винтиком в системе. Его основная цель — функционировать в качестве центральной базы данных, которая управляет функциями, прежде чем они будут отправлены для обучения модели или вывода.
Если вы не знакомы с этим термином, функции — это, по сути, необработанные данные, которые с помощью процесса, называемого разработкой функций, перерабатываются во что-то более полезное, что наши модели ML могут использовать для самообучения или расчета прогнозов.
Короче говоря, хранилища функций позволяют нам:
Повторно используйте и делитесь функциями между разными моделями и командами.
Сократите время, необходимое для экспериментов по машинному обучению
Минимизируйте неточные прогнозы из-за серьезного перекоса в обучении.
Чтобы лучше понять важность хранилища функций, вот схема конвейера машинного обучения, который его не использует.
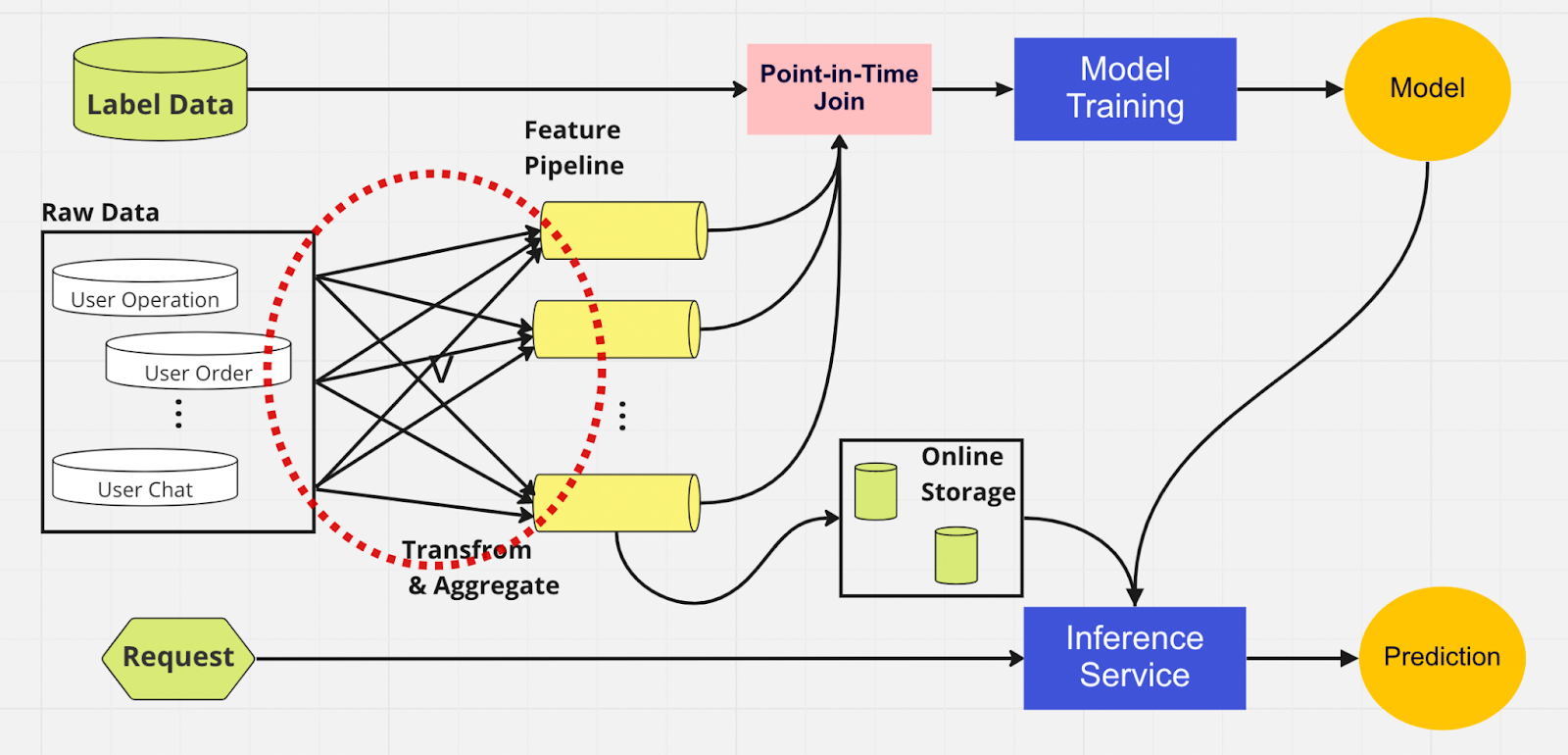
В этом конвейере две части — обучение модели и служба вывода — не могут определить, какие функции уже существуют и могут быть повторно использованы. Это приводит к тому, что конвейер ML дублирует процесс разработки функций. В красном круге на диаграмме вы заметите, что конвейер машинного обучения вместо повторного использования функций создал группу дублирующих функций и избыточных конвейеров. Мы называем это разрастанием конвейера функций.
Поддержание такого разрастания функций становится все более дорогостоящим и неуправляемым сценарием по мере того, как бизнес растет и на платформу приходит все больше пользователей. Подумайте об этом таким образом; специалист по данным должен начать процесс разработки функций, который является длительным и утомительным, полностью с нуля для каждой новой модели, которую он создает.
Кроме того, слишком частая повторная реализация логики функций приводит к появлению концепции, называемой неравномерностью обучения и обслуживания, которая представляет собой несоответствие между данными на этапе обучения и вывода. Это приводит к неточным прогнозам и непредсказуемому поведению модели, которое трудно устранить во время производства. Перед сохранением функций наши специалисты по данным проверяли согласованность функций с помощью проверок работоспособности. Это трудоемкий процесс, выполняемый вручную и отвлекающий внимание от более приоритетных задач, таких как моделирование и тщательное проектирование функций. Теперь давайте рассмотрим конвейер машинного обучения с хранилищем функций.

Как и в другом конвейере, с левой стороны у нас те же источники данных и функции. Однако вместо того, чтобы проходить через несколько конвейеров функций, у нас есть хранилище функций как один центральный узел, который обслуживает обе фазы конвейера ML (обучение модели и служба вывода). Нет дублирующих функций; все процессы, необходимые для создания объекта, включая преобразование и агрегирование, необходимо выполнить только один раз.
Ученые, работающие с данными, могут интуитивно взаимодействовать с хранилищем функций, используя наш специально созданный Python SDK, для поиска, повторного использования и обнаружения функций для последующего обучения и вывода моделей машинного обучения.
По сути, хранилище функций представляет собой централизованную базу данных, объединяющую оба этапа. А поскольку хранилище функций гарантирует согласованность функций для обучения и вывода, мы можем значительно уменьшить перекос в обслуживании обучения.
Обратите внимание, что хранилища функций делают гораздо больше, чем мы упомянули выше. Это, конечно, более элементарное изложение того, почему мы используем хранилище функций, которое мы можем разбить на несколько слов: подготовка и отправка функций в модели ML самым быстрым и простым способом.
Внутри магазина функций

На рисунке выше показан типичный макет хранилища функций, будь то AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio или Tetcom. Все хранилища функций предоставляют два типа хранения: онлайн и оффлайн.
Онлайн-хранилища функций используются для вывода в реальном времени, а автономные хранилища — для пакетного прогнозирования и обучения моделей. Из-за разных вариантов использования метрики, которые мы используем для оценки производительности, совершенно разные. В онлайн-функции мы стремимся к низкой задержке. Для автономных хранилищ функций нам нужна высокая пропускная способность.
Разработчики могут выбрать любой корпоративный магазин функций или даже открытый исходный код на основе технологического стека. На диаграмме ниже показаны ключевые различия между онлайн- и офлайн-магазинами в AWS SageMaker Feature Store.

Интернет-магазин: хранит самые последние копии функций и обслуживает их с малой задержкой в миллисекундах, скорость которой зависит от размера вашей полезной нагрузки. Для нашей модели захвата учетной записи (ATO), которая имеет восемь групп функций и всего 55 функций, скорость составляет около 30 мс с задержкой p99.
Автономное хранилище: хранилище, предназначенное только для добавления, которое позволяет отслеживать все исторические функции и позволяет путешествовать во времени, чтобы избежать утечки данных. Данные хранятся в формате паркета с разделением по времени для повышения эффективности чтения.
Что касается согласованности функций, если группа функций настроена как для онлайн-, так и для автономного использования, данные будут автоматически и внутренне копироваться в автономное хранилище, пока функция принимается интернет-магазином.
Как мы используем хранилище функций?

Код, изображенный выше, скрывает в себе большую сложность. Хранилища функций позволяют нам просто импортировать интерфейс Python для обучения модели и вывода.
Используя хранилище функций, наши специалисты по данным могут легко определять функции и создавать новые модели, не беспокоясь об утомительном процессе обработки данных на серверной стороне.
Лучшие практики использования хранилища функций
В нашей предыдущей публикации в блоге мы объяснили, как мы используем уровень хранилища для направления функций в централизованную базу данных. Здесь мы хотели бы поделиться двумя лучшими практиками использования хранилища функций:
Мы не принимаем функции, которые не изменились
Мы разделяем функции на две логические группы: активные пользовательские операции и неактивные.
Рассмотрим этот пример. Допустим, в вашем интернет-магазине функций для PutRecord установлен лимит регулирования 10 000 TPS. Используя эту гипотезу, мы получим функции для 100 миллионов пользователей. Мы не можем проглотить их все сразу, а с нашей текущей скоростью это займет около 2,7 часов. Чтобы решить эту проблему, мы решили использовать только недавно обновленные функции. Например, мы не будем использовать функцию, если значение не изменилось с момента ее последнего добавления.
Что касается второго момента, предположим, что вы поместили набор функций в одну логическую группу функций. Некоторые из них активны, тогда как большая часть неактивна, то есть большинство функций остаются неизменными. По нашему мнению, логичным шагом будет разделить активные и неактивные функции на две группы функций, чтобы ускорить процесс приема.
Для неактивных функций мы сокращаем 95% данных, которые нам необходимо принимать в хранилище функций для 100 миллионов пользователей на почасовой основе. Кроме того, мы по-прежнему сокращаем на 20 % объем данных, необходимых для активных функций. Таким образом, вместо трех часов конвейер пакетной обработки обрабатывает функции 100 миллионов пользователей за 10 минут.
Заключительные мысли
Подводя итог, можно сказать, что хранилища функций позволяют нам повторно использовать функции, ускорять разработку функций и минимизировать неточные прогнозы, сохраняя при этом согласованность между обучением и выводом.
Заинтересованы в использовании машинного обучения для защиты крупнейшей в мире криптоэкосистемы и ее пользователей? Посетите Binance Engineering/AI на нашей странице вакансий, чтобы найти открытые объявления о вакансиях.
Дальнейшее чтение:
(Блог) Использование MLOps для создания сквозного конвейера машинного обучения в реальном времени