
Oferă funcții de învățare automată precise, coerente și pregătite pentru producție.

Această bucată explorează magazinul nostru de funcții de învățare automată (ML) mai detaliat. Este o continuare a postării noastre anterioare pe blog, care oferă o imagine de ansamblu mai amplă a întregii infrastructuri ML.
De ce folosim un magazin de funcții?
Magazinul de caracteristici, una dintre numeroasele părți din conducta noastră, este, fără îndoială, cel mai important dinte din sistem. Scopul său principal este să funcționeze ca o bază de date centrală care gestionează caracteristicile înainte ca acestea să fie livrate pentru antrenament sau inferență de model.
Dacă nu sunteți familiarizat cu termenul, caracteristicile sunt în esență date brute care sunt rafinate, printr-un proces numit inginerie de caracteristici, în ceva mai utilizabil pe care modelele noastre ML îl pot folosi pentru a se antrena sau calcula predicții.
Pe scurt, magazinele de caracteristici ne permit să:
Reutilizați și partajați funcții în diferite modele și echipe
Scurtați timpul necesar pentru experimentele ML
Minimizați previziunile inexacte din cauza distorsiunii severe de antrenament-servire
Pentru a înțelege mai bine importanța unui magazin de caracteristici, iată o diagramă a unei conducte ML care nu folosește una.
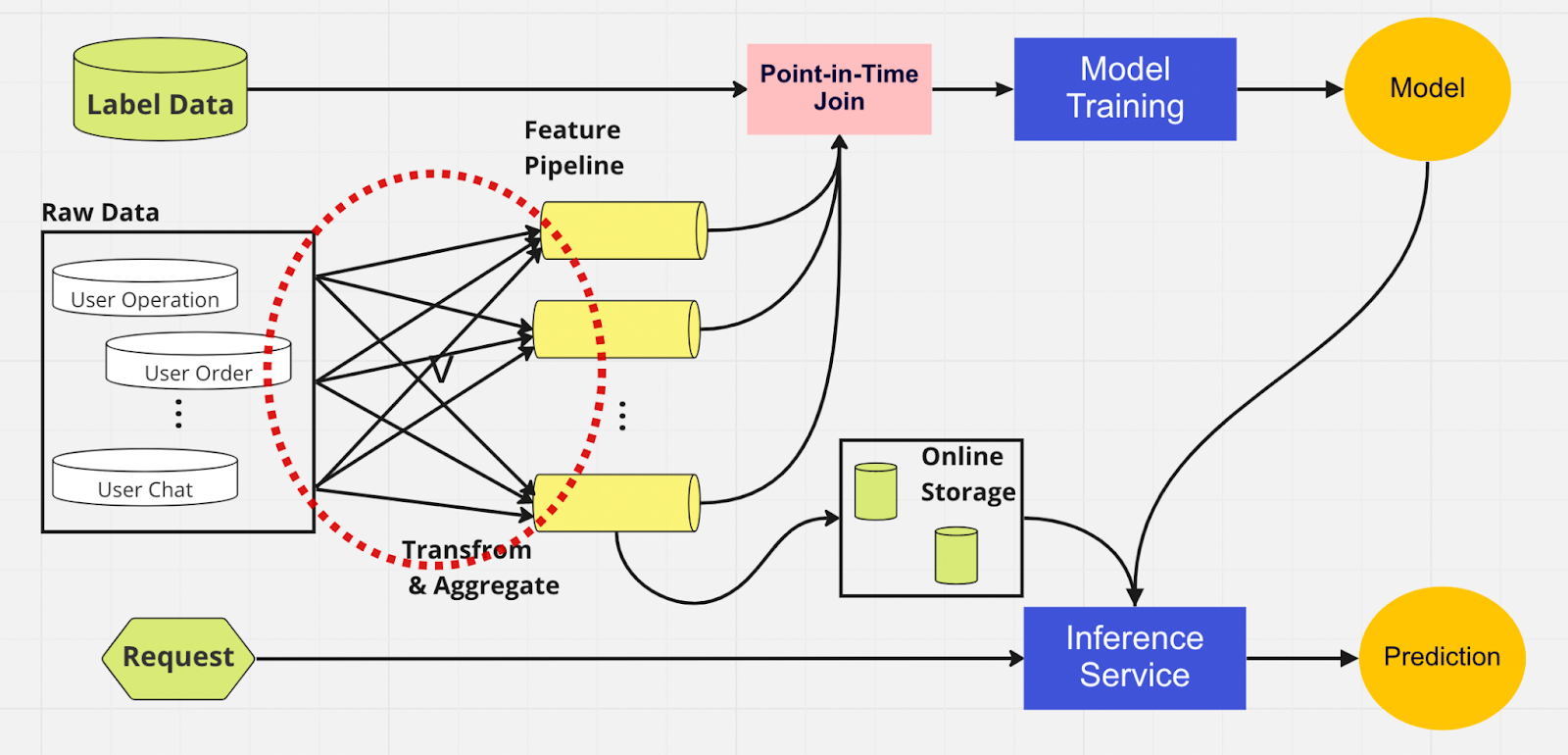
În această conductă, cele două părți – model de instruire și serviciu de inferență – nu pot identifica caracteristicile care există deja și pot fi reutilizate. Acest lucru duce la pipeline ML duplicând procesul de inginerie a caracteristicilor. Veți observa în cercul roșu de pe diagramă că conducta ML, în loc să reutilizeze caracteristici, a construit un grup de caracteristici duplicate și conducte redundante. Numim acest grup o extindere a conductei caracteristice.
Menținerea acestei extinderi de funcții devine un scenariu din ce în ce mai costisitor și mai greu de gestionat, pe măsură ce afacerea crește și mai mulți utilizatori intră pe platformă. Gândește-te la asta în acest fel; cercetătorul de date trebuie să înceapă procesul de inginerie a caracteristicilor, care este lung și plictisitor, complet de la zero pentru fiecare model nou pe care îl creează.
În plus, prea multă reimplementare a logicii caracteristicilor introduce un concept numit decalaj de instruire-servire, care este o discrepanță între date în timpul etapei de instruire și de inferență. Aceasta duce la predicții inexacte și la un comportament imprevizibil al modelului, care este greu de depanat în timpul producției. Înainte de a stoca caracteristici, oamenii noștri de știință de date ar verifica consistența caracteristicilor folosind verificări de sănătate. Acesta este un proces manual, consumator de timp, care abate atenția de la sarcinile cu prioritate mai mare, cum ar fi modelarea și ingineria perspicace a caracteristicilor. Acum, să explorăm o conductă ML cu un magazin de funcții.

Similar cu cealaltă conductă, avem aceleași surse de date și caracteristici în partea stângă. Cu toate acestea, în loc să trecem prin mai multe conducte de caracteristici, avem magazinul de caracteristici ca un hub central care deservește ambele faze ale conductei ML (serviciu de instruire și deducere a modelelor). Nu există caracteristici duplicate; toate procesele necesare pentru a construi o caracteristică, inclusiv transformarea și agregarea, trebuie efectuate o singură dată.
Oamenii de știință de date pot interacționa intuitiv cu magazinul de funcții folosind SDK-ul nostru Python personalizat pentru a căuta, reutiliza și descoperi funcții pentru antrenamentul și inferența modelului ML în aval.
În esență, magazinul de caracteristici este o bază de date centralizată care unifică ambele faze. Și, deoarece magazinul de caracteristici garantează caracteristici consistente pentru antrenament și inferență, putem reduce deformarea de servire a antrenamentului cu o sumă semnificativă.
Rețineți că magazinele de caracteristici fac mult mai mult decât punctele menționate mai sus. Acesta este, desigur, un rezumat mai rudimentar al motivului pentru care folosim un magazin de funcții și unul pe care îl putem descompune în doar câteva cuvinte: pregătiți și trimiteți funcții în modelele ML în cel mai rapid și mai ușor mod posibil.
În interiorul Magazinului de caracteristici

Figura de mai sus arată aspectul tipic al magazinului de funcții, fie că este AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio sau Tetcom. Toate magazinele de caracteristici oferă două tipuri de stocare: online sau offline.
Magazinele de caracteristici online sunt folosite pentru inferențe în timp real, în timp ce magazinele de caracteristici offline sunt folosite pentru predicția loturilor și formarea modelelor. Datorită diferitelor cazuri de utilizare, valoarea pe care o folosim pentru a evalua performanța este complet diferită. Într-o funcție online, căutăm o latență scăzută. Pentru magazinele de caracteristici offline, dorim un randament ridicat.
Dezvoltatorii pot alege orice magazin de caracteristici de întreprindere sau chiar open source pe baza stivei de tehnologie. Diagrama de mai jos prezintă diferențele cheie dintre magazinele online și offline din AWS SageMaker Feature Store.

Magazin online: stochează cea mai recentă copie a caracteristicilor și le servește cu o latență scăzută în milisecunde, a cărei viteză depinde de dimensiunea sarcinii dvs. utile. Pentru modelul nostru de preluare a contului (ATO), care are opt grupuri de caracteristici și 55 de caracteristici în total, viteza este de aproximativ 30 ms p99 latență.
Magazin offline: un magazin numai pentru atașare, care vă permite să urmăriți toate caracteristicile istorice și să permiteți călătoria în timp pentru a evita scurgerea de date. Datele sunt stocate în format parchet cu partiție în timp pentru a crește eficiența citirii.
În ceea ce privește coerența caracteristicilor, atâta timp cât grupul de caracteristici este configurat atât pentru utilizarea online, cât și pentru utilizarea offline, datele vor fi copiate automat și intern în magazinul offline în timp ce caracteristica este ingerată de magazinul online.
Cum folosim magazinul de funcții?

Codul din imaginea de mai sus ascunde multă complexitate. Magazinele de caracteristici ne permit să importăm pur și simplu interfața Python pentru antrenamentul modelului și inferența.
Folosind magazinul de caracteristici, oamenii noștri de știință de date pot defini cu ușurință caracteristici și pot construi noi modele fără a fi nevoiți să vă faceți griji cu privire la procesul obositor de inginerie a datelor din backend.
Cele mai bune practici pentru utilizarea unui magazin de funcții
În postarea anterioară pe blog, am explicat cum folosim un strat de magazin pentru a canaliza funcțiile în DB centralizat. Aici, am dori să împărtășim două bune practici atunci când folosim un magazin de funcții:
Nu ingerăm funcții care nu s-au schimbat
Separăm funcțiile în două grupuri logice: operațiunile utilizator active și inactive
Luați în considerare acest exemplu. Să presupunem că aveți o limită de limitare de 10K TPS pentru PutRecord în magazinul dvs. de funcții online. Folosind acest ipotetic, vom asimila funcții pentru 100 de milioane de utilizatori. Nu le putem ingera pe toate deodată și, cu viteza noastră actuală, va dura aproximativ 2,7 ore pentru a termina. Pentru a rezolva acest lucru, alegem doar să ingerăm funcții actualizate recent. De exemplu, nu vom ingera o caracteristică dacă valoarea nu s-a schimbat de la ultima dată când a fost ingerată.
Pentru al doilea punct, să presupunem că puneți un set de caracteristici într-un grup logic de caracteristici. Unele sunt active, în timp ce o mare parte este inactivă, ceea ce înseamnă că majoritatea funcțiilor sunt neschimbate. Pasul logic, în opinia noastră, este împărțirea activelor și inactivelor în două grupuri de caracteristici pentru a accelera procesul de asimilare.
Pentru funcțiile inactive, reducem cu 95% din datele pe care trebuie să le ingerăm în magazinul de funcții pentru 100 de milioane de utilizatori, pe oră, în pipeline de funcții. În plus, reducem în continuare cu 20% din datele necesare pentru funcțiile active. Așadar, în loc de trei ore, conducta de asimilare în loturi procesează funcțiile a 100 de milioane de utilizatori în 10 minute.
Gânduri de închidere
Pentru a rezuma, magazinele de funcții ne permit să refolosim funcțiile, să accelerăm ingineria caracteristicilor și să minimizăm predicțiile inexacte - totodată menținând coerența între instruire și inferență.
Vă interesează să utilizați ML pentru a proteja cel mai mare ecosistem cripto din lume și utilizatorii săi? Consultați Binance Engineering/AI pe pagina noastră de cariere pentru postări de locuri de muncă deschise.
Lectură suplimentară:
(Blog) Utilizarea MLOps pentru a construi o conductă de învățare automată end-to-end în timp real