
Dostarczanie dokładnych, spójnych i gotowych do produkcji funkcji uczenia maszynowego.

W tym artykule bardziej szczegółowo omawiamy nasz sklep z funkcjami uczenia maszynowego (ML). Jest to kontynuacja naszego poprzedniego wpisu na blogu, który zapewnia szerszy przegląd całej infrastruktury potoku ML.
Dlaczego korzystamy ze sklepu z funkcjami?
Magazyn funkcji, jedna z wielu części naszego projektu, jest prawdopodobnie najważniejszym trybem w systemie. Jego głównym celem jest działanie jako centralna baza danych zarządzająca funkcjami, zanim zostaną one wysłane do uczenia modeli lub wnioskowania.
Jeśli nie znasz tego terminu, funkcje to zasadniczo surowe dane, które są udoskonalane w procesie zwanym inżynierią funkcji w coś bardziej użytecznego, czego nasze modele uczenia maszynowego mogą używać do uczenia się lub obliczania prognoz.
Krótko mówiąc, sklepy z funkcjami pozwalają nam:
Wykorzystuj ponownie i udostępniaj funkcje różnym modelom i zespołom
Skróć czas wymagany na eksperymenty ML
Zminimalizuj niedokładne przewidywania z powodu poważnego odchylenia w zakresie treningu
Aby lepiej zrozumieć znaczenie magazynu funkcji, oto diagram potoku ML, który go nie używa.
W tym procesie dwie części — szkolenie modeli i usługa wnioskowania — nie są w stanie zidentyfikować, które funkcje już istnieją i można je ponownie wykorzystać. Prowadzi to do tego, że potok ML powiela proces inżynierii funkcji. W czerwonym kółku na diagramie zauważysz, że potok ML zamiast ponownie wykorzystywać funkcje, utworzył grupę zduplikowanych funkcji i zbędnych potoków. Nazywamy to skupiskiem rozrastającym się potokiem obiektów.
Utrzymanie tak dużej liczby funkcji staje się scenariuszem coraz kosztownym i niemożliwym do zarządzania w miarę rozwoju firmy i coraz większej liczby użytkowników wchodzących na platformę. Pomyśl o tym w ten sposób; analityk danych musi rozpoczynać proces inżynierii funkcji, który jest długi i żmudny, całkowicie od zera dla każdego nowego tworzonego modelu.
Ponadto zbyt duża reimplementacja logiki cech wprowadza koncepcję zwaną skośnością uczenia, która polega na rozbieżności między danymi na etapie uczenia i wnioskowania. Prowadzi to do niedokładnych przewidywań i nieprzewidywalnego zachowania modelu, które trudno rozwiązać podczas produkcji. Przed magazynowaniem funkcji nasi analitycy danych sprawdzaliby spójność funkcji za pomocą kontroli poprawności. Jest to ręczny, czasochłonny proces, który odwraca uwagę od zadań o wyższym priorytecie, takich jak modelowanie i wnikliwa inżynieria funkcji. Przyjrzyjmy się teraz potokowi uczenia maszynowego z magazynem funkcji.

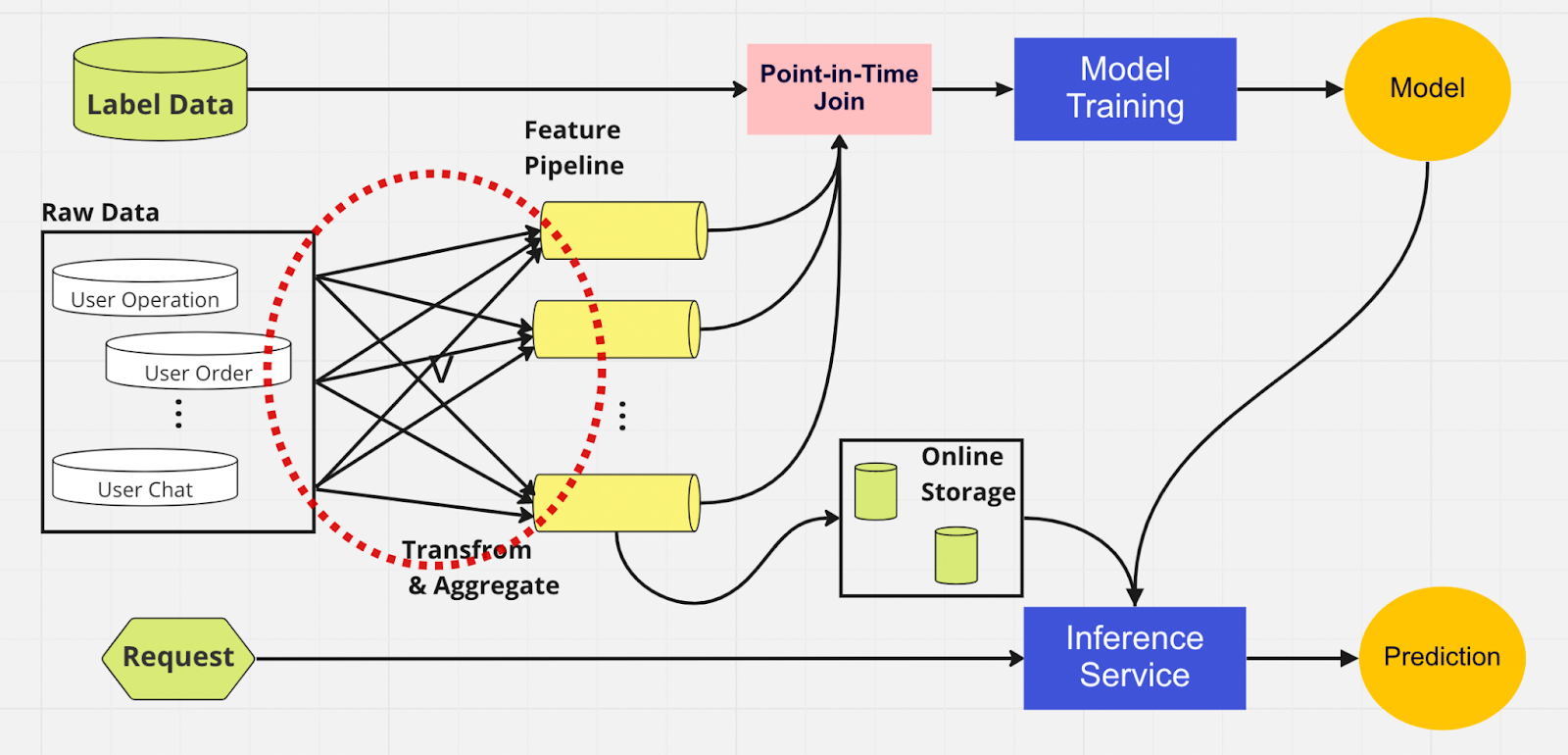
Podobnie jak w przypadku drugiego potoku, po lewej stronie mamy te same źródła danych i funkcje. Jednak zamiast przechodzić przez wiele potoków funkcji, mamy magazyn funkcji jako jeden centralny węzeł, który obsługuje obie fazy potoku ML (uczenie modeli i usługa wnioskowania). Nie ma zduplikowanych funkcji; wszystkie procesy wymagane do zbudowania funkcji, w tym transformacja i agregacja, wystarczy wykonać tylko raz.
Analitycy danych mogą intuicyjnie wchodzić w interakcję ze magazynem funkcji, korzystając z naszego niestandardowego zestawu SDK języka Python, aby wyszukiwać, ponownie wykorzystywać i odkrywać funkcje na potrzeby dalszego uczenia i wnioskowania modelu ML.
Zasadniczo magazyn funkcji jest scentralizowaną bazą danych, która jednoczy obie fazy. A ponieważ magazyn funkcji gwarantuje spójne funkcje uczenia i wnioskowania, możemy znacznie zmniejszyć zniekształcenie w obsłudze uczenia.
Pamiętaj, że sklepy z funkcjami robią znacznie więcej niż punkty, o których wspomnieliśmy powyżej. Jest to oczywiście bardziej podstawowe podsumowanie tego, dlaczego używamy magazynu funkcji, i które możemy podzielić na kilka słów: przygotowanie i przesłanie funkcji do modeli uczenia maszynowego w najszybszy i najłatwiejszy możliwy sposób.
Wewnątrz sklepu z funkcjami

Powyższy rysunek przedstawia typowy układ sklepu z funkcjami, niezależnie od tego, czy jest to sklep z funkcjami AWS SageMaker, Google Vertex AI (Feast), Azure (Feathr), Iguazio czy Tetcom. Wszystkie sklepy z funkcjami zapewniają dwa typy przechowywania: online i offline.
Magazyny funkcji online służą do wnioskowania w czasie rzeczywistym, natomiast magazyny funkcji offline służą do przewidywania wsadowego i uczenia modeli. Ze względu na różne przypadki użycia mierniki, których używamy do oceny wydajności, są zupełnie inne. W przypadku funkcji online szukamy małych opóźnień. W przypadku sklepów z funkcjami offline chcemy dużej przepustowości.
Programiści mogą wybrać dowolny sklep z funkcjami dla przedsiębiorstw lub nawet oprogramowanie typu open source w oparciu o stos technologii. Poniższy diagram przedstawia kluczowe różnice pomiędzy sklepami online i offline w sklepie z funkcjami AWS SageMaker.

Sklep internetowy: przechowuje najnowszą kopię funkcji i udostępnia je z niskimi opóźnieniami milisekundowymi, których prędkość zależy od rozmiaru ładunku. W przypadku naszego modelu przejęcia konta (ATO), który obejmuje osiem grup funkcji i łącznie 55 funkcji, prędkość wynosi około 30 ms opóźnienia p99.
Sklep offline: sklep z możliwością dodawania, który pozwala śledzić wszystkie funkcje historyczne i umożliwia podróże w czasie, aby uniknąć wycieku danych. Dane są przechowywane w formacie parkietu z podziałem czasowym w celu zwiększenia wydajności odczytu.
Jeśli chodzi o spójność funkcji, o ile grupa funkcji jest skonfigurowana do użytku zarówno w trybie online, jak i offline, dane będą automatycznie i wewnętrznie kopiowane do sklepu offline, gdy funkcja będzie przetwarzana przez sklep internetowy.
Jak korzystamy ze sklepu z funkcjami?

Kod pokazany powyżej skrywa dużą złożoność. Magazyny funkcji pozwalają nam po prostu zaimportować interfejs Pythona w celu uczenia modeli i wnioskowania.
Korzystając z magazynu funkcji, nasi analitycy danych mogą z łatwością definiować funkcje i budować nowe modele, nie martwiąc się o żmudny proces inżynierii danych w zapleczu.
Najlepsze praktyki dotyczące korzystania ze sklepu z funkcjami
W naszym poprzednim poście na blogu wyjaśniliśmy, w jaki sposób używamy warstwy sklepu do przesyłania funkcji do scentralizowanej bazy danych. W tym miejscu chcielibyśmy podzielić się dwiema najlepszymi praktykami dotyczącymi korzystania ze sklepu z funkcjami:
Nie przyjmujemy funkcji, które się nie zmieniły
Funkcje dzielimy na dwie logiczne grupy: aktywne operacje użytkownika i nieaktywne
Rozważmy ten przykład. Załóżmy, że masz limit dławienia 10 000 TPS dla PutRecord w swoim internetowym sklepie z funkcjami. Korzystając z tego hipotetycznego założenia, pozyskamy funkcje dla 100 milionów użytkowników. Nie możemy połknąć ich wszystkich na raz, a przy naszej obecnej prędkości ukończenie zajmie około 2,7 godziny. Aby rozwiązać ten problem, decydujemy się na pobieranie tylko ostatnio zaktualizowanych funkcji. Na przykład nie przetworzymy funkcji, jeśli jej wartość nie uległa zmianie od ostatniego pobrania.
W drugim punkcie załóżmy, że umieściłeś zestaw funkcji w jednej logicznej grupie funkcji. Niektóre są aktywne, a duża część jest nieaktywna, co oznacza, że większość funkcji pozostaje niezmieniona. Naszym zdaniem logicznym krokiem jest podzielenie aktywnych i nieaktywnych na dwie grupy funkcji, aby przyspieszyć proces przetwarzania.
W przypadku nieaktywnych funkcji zmniejszamy 95% danych, które musimy pozyskać do magazynu funkcji dla 100 milionów użytkowników co godzinę. Ponadto nadal zmniejszamy o 20% dane wymagane do aktywnych funkcji. Zatem zamiast trzech godzin potok przetwarzania wsadowego przetwarza funkcje warte 100 milionów użytkowników w 10 minut.
Zamykające myśli
Podsumowując, magazyny funkcji pozwalają nam ponownie wykorzystywać funkcje, przyspieszać projektowanie funkcji i minimalizować niedokładne przewidywania — a wszystko to przy jednoczesnym zachowaniu spójności między uczeniem a wnioskowaniem.
Interesuje Cię wykorzystanie ML do ochrony największego na świecie ekosystemu kryptograficznego i jego użytkowników? Sprawdź Binance Engineering/AI na naszej stronie karier, aby zobaczyć otwarte oferty pracy.
Dalsza lektura:
(Blog) Wykorzystanie MLOps do zbudowania kompleksowego potoku uczenia maszynowego w czasie rzeczywistym