
Fornire funzionalità di machine learning accurate, coerenti e pronte per la produzione.

Questo articolo esplora il nostro archivio di funzionalità di machine learning (ML) in modo più dettagliato. È una continuazione del nostro post precedente sul blog che fornisce una panoramica più ampia dell'intera infrastruttura della pipeline ML.
Perché utilizziamo un negozio di funzionalità?
L'archivio delle funzionalità, una delle tante parti della nostra pipeline, è senza dubbio l'ingranaggio più importante del sistema. Il suo scopo principale è quello di funzionare come un database centrale che gestisce le funzionalità prima che vengano spedite per l'addestramento o l'inferenza del modello.
Se non hai familiarità con il termine, le funzionalità sono essenzialmente dati grezzi che vengono perfezionati, attraverso un processo chiamato ingegneria delle funzionalità, in qualcosa di più utilizzabile che i nostri modelli ML possono utilizzare per addestrarsi o calcolare previsioni.
In poche parole, i feature store ci consentono di:
Riutilizza e condividi funzionalità tra modelli e team diversi
Riduci il tempo necessario per gli esperimenti di machine learning
Riduci al minimo le previsioni imprecise dovute a gravi distorsioni del servizio di formazione
Per comprendere meglio l'importanza di un feature store, ecco un diagramma di una pipeline ML che non ne utilizza uno.
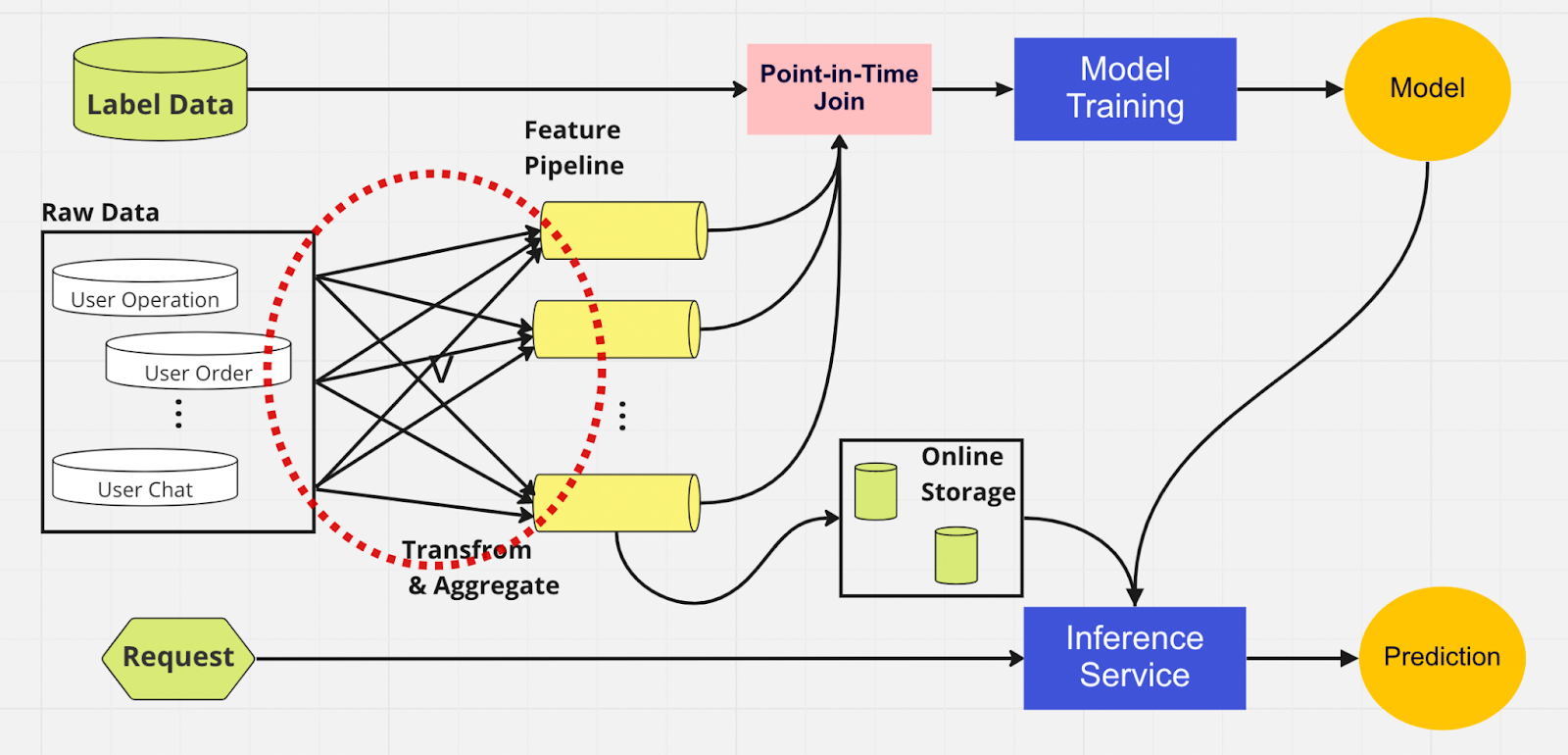
In questa pipeline, le due parti – training del modello e servizio di inferenza – non sono in grado di identificare quali funzionalità già esistono e possono essere riutilizzate. Ciò porta la pipeline ML a duplicare il processo di ingegneria delle funzionalità. Noterai nel cerchio rosso sul diagramma che la pipeline ML, invece di riutilizzare le funzionalità, ha creato un insieme di funzionalità duplicate e pipeline ridondanti. Chiamiamo questo gruppo un'espansione incontrollata della pipeline di funzionalità.
Mantenere questa espansione di funzionalità diventa uno scenario sempre più costoso e ingestibile man mano che l’azienda cresce e sempre più utenti accedono alla piattaforma. Pensaci in questo modo; il data scientist deve avviare il processo di progettazione delle funzionalità, che è lungo e noioso, interamente da zero per ogni nuovo modello creato.
Inoltre, una reimplementazione eccessiva della logica delle funzionalità introduce un concetto chiamato distorsione del servizio di training, che è una discrepanza tra i dati durante la fase di training e di inferenza. Porta a previsioni imprecise e a un comportamento imprevedibile del modello che è difficile da risolvere durante la produzione. Prima degli archivi di funzionalità, i nostri data scientist verificavano la coerenza delle funzionalità utilizzando controlli di integrità. Si tratta di un processo manuale che richiede molto tempo e che distoglie l'attenzione da attività con priorità più elevata come la modellazione e l'ingegneria approfondita delle funzionalità. Ora esploriamo una pipeline di machine learning con un archivio di funzionalità.

Analogamente all'altra pipeline, abbiamo le stesse origini dati e funzionalità sul lato sinistro. Tuttavia, invece di passare attraverso più pipeline di funzionalità, abbiamo l'archivio di funzionalità come un hub centrale che serve entrambe le fasi della pipeline ML (addestramento del modello e servizio di inferenza). Non sono presenti funzionalità duplicate; tutti i processi necessari per creare una funzionalità, comprese la trasformazione e l'aggregazione, devono essere eseguiti una sola volta.
I data scientist possono interagire in modo intuitivo con l'archivio di funzionalità utilizzando il nostro SDK Python personalizzato per cercare, riutilizzare e scoprire funzionalità per l'addestramento e l'inferenza del modello ML downstream.
Essenzialmente, l'archivio delle funzionalità è un database centralizzato che unifica entrambe le fasi. E poiché l'archivio delle funzionalità garantisce funzionalità coerenti per l'addestramento e l'inferenza, possiamo ridurre in modo significativo la distorsione del servizio di addestramento.
Tieni presente che i feature store fanno molto di più dei punti menzionati sopra. Questo è, ovviamente, un riepilogo più rudimentale del motivo per cui utilizziamo un archivio di funzionalità e che possiamo ulteriormente scomporre in poche parole: preparare e inviare funzionalità ai modelli ML nel modo più semplice e veloce possibile.
All'interno del Feature Store

La figura sopra mostra il layout tipico del negozio di funzionalità, che si tratti di AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio o Tetcom. Tutti i feature store forniscono due tipi di archiviazione: online o offline.
Gli archivi di funzionalità online vengono utilizzati per l'inferenza in tempo reale, mentre gli archivi di funzionalità offline vengono utilizzati per la previsione batch e l'addestramento del modello. A causa dei diversi casi d’uso, la metrica che utilizziamo per valutare le prestazioni è completamente diversa. In una funzionalità online, cerchiamo una bassa latenza. Per gli store di funzionalità offline, vogliamo un throughput elevato.
Gli sviluppatori possono scegliere qualsiasi archivio di funzionalità aziendali o anche open source in base allo stack tecnologico. Il diagramma seguente illustra le principali differenze tra i negozi online e offline nel negozio di funzionalità AWS SageMaker.

Negozio online: archivia la copia più recente delle funzionalità e le fornisce con una latenza di pochi millisecondi, la cui velocità dipende dalle dimensioni del carico utile. Per il nostro modello di account takeover (ATO), che ha otto gruppi di funzionalità e 55 funzionalità in totale, la velocità è di circa 30 ms di latenza p99.
Negozio offline: un negozio di sola aggiunta che consente di tenere traccia di tutte le funzionalità storiche e consentire il viaggio nel tempo per evitare perdite di dati. I dati vengono archiviati in formato parquet con partizionamento temporale per aumentare l'efficienza di lettura.
Per quanto riguarda la coerenza delle funzionalità, purché il gruppo di funzionalità sia configurato per l'utilizzo sia online che offline, i dati verranno copiati automaticamente e internamente nel negozio offline mentre la funzionalità viene acquisita dal negozio online.
Come utilizziamo il Feature Store?

Il codice nella foto sopra nasconde molta complessità. Gli archivi di funzionalità ci consentono di importare semplicemente l'interfaccia Python per l'addestramento e l'inferenza del modello.
Utilizzando l'archivio delle funzionalità, i nostri data scientist possono definire facilmente funzionalità e creare nuovi modelli senza doversi preoccupare del noioso processo di ingegneria dei dati nel backend.
Best practice per l'utilizzo di un archivio di funzionalità
Nel nostro precedente post sul blog, abbiamo spiegato come utilizziamo un livello negozio per incanalare le funzionalità nel DB centralizzato. Qui, vorremmo condividere due best practice quando si utilizza un feature store:
Non ingeriamo funzionalità che non sono cambiate
Separiamo le funzionalità in due gruppi logici: operazioni utente attive e inattive
Considera questo esempio. Supponiamo che tu abbia un limite di limitazione di 10K TPS per PutRecord sul tuo negozio di funzionalità online. Utilizzando questo ipotetico, inseriremo funzionalità per 100 milioni di utenti. Non possiamo acquisirli tutti in una volta e, con la nostra velocità attuale, ci vorranno circa 2,7 ore per completarli. Per risolvere questo problema, scegliamo solo di importare funzionalità aggiornate di recente. Ad esempio, non acquisiremo una funzionalità se il valore non è cambiato dall'ultima volta che è stata acquisita.
Per il secondo punto, supponiamo di inserire una serie di funzionalità in un gruppo di funzionalità logico. Alcuni sono attivi, mentre gran parte è inattiva, il che significa che la maggior parte delle funzionalità sono invariate. Il passo logico, a nostro avviso, è dividere le funzioni attive e inattive in due gruppi di funzionalità per accelerare il processo di acquisizione.
Per le funzionalità inattive, riduciamo il 95% dei dati che dobbiamo inserire nell'archivio di funzionalità per 100 milioni di utenti su base oraria. Inoltre, riduciamo comunque il 20% dei dati richiesti per le funzionalità attive. Pertanto, invece di tre ore, la pipeline di acquisizione batch elabora 100 milioni di funzionalità di utenti in 10 minuti.
Pensieri conclusivi
Per riassumere, gli archivi di funzionalità ci consentono di riutilizzare le funzionalità, accelerarne la progettazione e ridurre al minimo le previsioni imprecise, mantenendo allo stesso tempo la coerenza tra training e inferenza.
Ti interessa utilizzare il machine learning per salvaguardare il più grande ecosistema crittografico del mondo e i suoi utenti? Dai un'occhiata a Binance Engineering/AI sulla nostra pagina delle carriere per le offerte di lavoro aperte.
Ulteriori letture:
(Blog) Utilizzo di MLOps per creare una pipeline di machine learning end-to-end in tempo reale