Continuing from the previous two articles on matters needing attention in programmatic trading:
Hard-core dry goods - details and thoughts on automated real-time trading of quantitative trading systems (1. Problems and difficulties)
Quantitative Trading System - Automated Firm Offer Details and Thoughts (2. Firm Offer Purpose)
Here we will continue to talk about some detailed handling skills in code design.
database
As mentioned in the previous two articles, the status record of a more complex strategy combination is very important and requires the use of a database.
In fact, most programming businesses can be classified into the CRUD category, that is, the core process is just adding, deleting, modifying and checking the database. Trading codes are no exception. Medium and low-frequency secondary market trading behavior is actually not much different from when people go shopping on a certain treasure. They are both buying and selling. The focus of automated trading lies in the management of strategic status.
If you are not already familiar with relational databases such as SQL, it is recommended that you directly learn to use NoSQL in-memory databases such as Redis. Its advantages are that it is easy to get started, has excellent performance, and is inherently single-threaded. There is no need to consider low-level operations such as locking data when reading and writing. However, the disadvantage is that there is no primary key and functions such as automatic number increment cannot be realized. If necessary, you have to write code to implement it yourself. However, I have never used this function in automated trading for so long.
Another unimportant issue is that for in-memory databases, if the amount of data that needs to be stored is relatively large, then the server memory must be larger. However, for general quantitative trading, 4G or even 2G of memory is enough and is not needed. Save so much data.
Redis is really powerful in the real world. If your strategy has high-frequency requirements, it can also implement the pub/sub message subscription model, eliminating the need to add various additional MQ modules. If you use a relational database like MySQL, as mentioned earlier, as long as you have not used it in practice before, you will have to invest time and energy in learning SQL, a relatively disgusting and difficult programming language. Note that everyone is here to do quantitative trading, not to learn to write code. Try to use a simpler solution.
In addition, if you want to build a market center, considering the performance, you will also use the Redis database and cooperate with the message queue for convenience. The solution is simple and suitable for most scenarios. One server (or multiple servers) can be used.
code design
Basically, when writing code, the core data structure is the most important. The data structure design is not reasonable enough, and the code will be written awkwardly, because it will inevitably cause the various modules to be coupled together, making modifications very troublesome. But to design it properly, you need some trading experience, that is, business experience. These are all about how to write code, there is not much to say. Everyone’s strategies are different and cannot be treated equally. However, some principles are probably the same.
For example, after an order is submitted, there is no guarantee of success, even if it is a market order, because it may be rejected by the exchange. For example, the exchange is too busy, or temporary network data packet loss occurs. Then, it is best to design some intermediate states similar to 2 Phase Commit. If it fails, keep trying (of course not too frequently, otherwise it will be banned if it exceeds the limit. There is a special retry decorator to do this), or add more method to correct the error state.
Under normal circumstances, even if the exchange is down, it will recover in a short time. If you don’t recover, then one party will be completely down, either the exchange or your own code server. This needs to be monitored and alerted. It is impossible for automated code to cover everything. If it cannot be processed automatically, an alarm will be issued. Manual intervention is required. If manual processing is not handled in time, as long as we do not continue to open positions to increase exposure, the problem will not be too big, because there are algorithmic stop-loss orders to cover the bottom.
The following is a strategy opening logic that I sorted out myself:
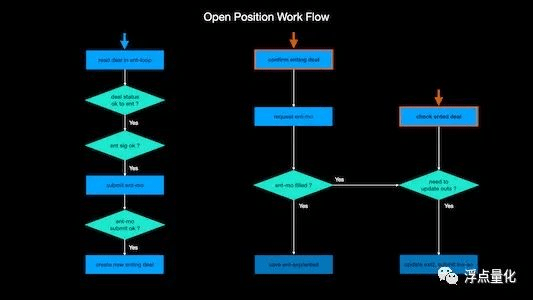
Basically, by drawing a similar flowchart, the code will be much more organized and the number of potential bugs will be reduced. Therefore, before writing code, it is best to draw a flow chart or sort it out while writing, so that the logic will be clear and you will have an idea.
The logic of closing a position is much more complicated than this, because there are more conditions for closing a position, such as stop-profit, stop-loss, and exit signals of various strategies, which will trigger the closing of the position. In short, the importance of exit is higher than that of entry, and the real offer is also a little more troublesome.
Because everyone’s strategy logic is definitely different, I won’t go into details here. The main thing is to straighten out your strategic logic and prevent various possible errors from happening.
However, these seem complicated, and they are just a bunch of if elses (Python doesn’t even have a switch statement). If the conditions are met, proceed to the next step. If not, exit. No big problem.
time control
When doing transactions, timing is undoubtedly very important. Here I will share some more of my time control skills.
In general programming, if there are tasks that need to be executed regularly, cron job packages such as apscheduler are usually used. For example, plan a scheduled task to detect whether the K-line price needs to open or close a position as soon as the hour arrives.
This kind of package actually opens a new thread immediately at the set time (can be accurate to the second level), and then executes the specified task. The problem is that if the execution time of this task is too long, then the next task will start again. There will be problems. Although they can be solved, they are more troublesome.
I usually use such scheduled tasks when I need to output log information regularly and perform program self-correction and self-test, which are low-frequency functions that can be completed quickly. These functions only read the data in the database, and there are no write or update operations, so it doesn't hurt to let apscheduler open another thread for processing.
However, logic that requires constant and frequent querying of market prices or local policy status is not suitable for such a timing package and needs to be controlled by a while loop.
For example, if the strategy uses signals within the bar of the K-line, it means that the signal may appear at any time, and you need to constantly check the underlying price or trading volume to determine whether corresponding operations need to be performed. If you need more precise time control at this time, for example, only execute the series logic of opening a position 10 seconds before the end of the k-line hour. So how can you simply judge whether it is the last 10 seconds?
I took the remainder of 3600 by using timestamp.
(If you are not familiar with the timestamp on the computer, that is, the timestamp, it starts from Greenwich Mean Time 1970.1.1. For example, it is about the 1691240298th second. There is no problem with the computer being accurate to the microsecond level.)
After taking the remainder from 3600, if the remainder is greater than 3590 seconds, it is the last ten seconds. The error can be down to the millisecond level. As mentioned before, it is best for the main transaction operations to be executed sequentially in one thread. In this way, the execution time can be roughly controlled, or the time period can be blurred, which will be no problem.
This kind of control requires that the time setting of your own server does not deviate greatly from the standard time. However, this kind of control will not be very precise, it can only reach the second level. However, Python cannot control time very precisely, and those sleep functions will cause errors of about microseconds.
Reduce API access frequency
If you have adopted an independent market center based on websocket to share market public information such as K-lines between different strategies or even different trading codes, then there is no concern about API frequency limitations in this regard.
But we also need to obtain account information in a timely manner, that is, three types of information: funds, positions, and orders. Although the account information can also use websocket and wait for the exchange server to actively push it, it is simpler to directly use the rest api for three reasons.
First, in order to reduce the burden on the account information pushed by websocket, the exchange requires the exchange to reconnect or update the listenKey every once in a while (Binance is 60 minutes). This situation is obviously more troublesome to maintain. Although it's not much trouble, if you do API hosting and trade multiple accounts at the same time, you have to activate a separate program to ensure the real-time accuracy of the information, and the logic becomes a lot more complicated.
Second, some exchanges do not have websocket push for account information updates. In this case, the trading logic is not universal, and it is more troublesome to switch real trading codes between different exchanges. Of course, most people will not trade on multiple exchanges and will not encounter such a situation.
Third, if the websocket link is broken, or encounters problems such as listenKey update or expiration mentioned earlier, if the program does not discover it in time, and there happens to be a transaction at this time, then if you only rely on websocket, it will cause a comparison Big problem, because missed account update information will not be pushed again. To avoid the possibility of such potential problems, you must also rely on the rest api to obtain certain account information. So in the end you have to rely on the rest api, isn't it unnecessary?
In summary, for medium and low-frequency transactions, it is better to directly use rest api to obtain account information. For important data sources, it is best to follow SSOT (Single Source Of Truth), otherwise it may cause potential confusion. This concept can be Googled by yourself and is very useful in programming that relies on data processing.
Then, if you only use the REST API to obtain account information, you can maintain a temporary account information table in the local code memory, especially the available funds. This can reduce frequent visits to the exchange. The key is to be fast, and you can send all the orders at once. Similar to placing orders in batches, and then slowly processing the logic behind the update, the faster the order is placed, the smaller the slippage will naturally be.
In addition, to determine whether the algorithmic stop-loss order has been filled, you can use the recent high and low prices instead of directly obtaining the status of the pending order, because to determine whether the order has been filled, you need to poll continuously, which is relatively frequent and will cause a lot of invalid api access. The K-line price update of websocket is very timely and does not occupy the API frequency limit.
In the same way, some exit orders can also be like this. If your exit signal relies on price within a bar, it may be better to use recent high and low prices. Because sometimes the price triggers and then returns immediately, if your checking frequency is not too high, you may miss it. To ensure consistency in your trading strategy, check high and low so prices are not missed. This approach has the added benefit that the actual transaction price may be more favorable than the real trigger price.
I don’t know if the above two points are easy to understand. It may require some real-life experience.
I would like to share some of my experience in developing real code, hoping it will be helpful to everyone.