

Über ZKML: ZKML (Zero Knowledge Machine Learning) ist eine Technologie für maschinelles Lernen, die wissensfreie Beweise und Algorithmen für maschinelles Lernen kombiniert, um Datenschutzprobleme beim maschinellen Lernen zu lösen.
Über verteilte Rechenleistung: Unter verteilter Rechenleistung versteht man die Zerlegung einer Rechenaufgabe in mehrere kleine Aufgaben und die Zuweisung dieser kleinen Aufgaben zur Verarbeitung an mehrere Computer oder Prozessoren, um eine effiziente Rechenleistung zu erreichen.

Die aktuelle Situation von KI und Web3: Außer Kontrolle geratener Bienenschwarm und Entropieanstieg
In „Out of Control: The New Biology of Machines, Society and the Economy“ schlug Kevin Kelly einmal ein Phänomen vor: Das Bienenvolk wird in einem Gruppentanz nach verteiltem Management Wahlentscheidungen treffen, und das gesamte Bienenvolk wird dieser Gruppe folgen Tanz. Der größte Schwarm der Welt dominiert eine Veranstaltung. Dies ist auch die von Maurice Maeterlinck erwähnte sogenannte „Seele des Bienenvolkes“ – jede Biene kann ihre eigene Entscheidung treffen und andere Bienen anleiten, um sie zu bestätigen, und die endgültige Entscheidung liegt wirklich bei der Gruppe.

Das Gesetz der Entropiezunahme und Unordnung selbst folgt dem Gesetz der Thermodynamik. Die theoretische Umsetzung in der Physik besteht darin, eine bestimmte Anzahl von Molekülen in eine leere Box zu geben und das endgültige Verteilungsprofil zu messen. Spezifisch für Menschen können die durch Algorithmen erzeugten Mengen trotz individueller Denkunterschiede Gruppenregeln aufweisen. Sie sind aufgrund von Faktoren wie der Zeit oft in einer leeren Box eingeschränkt und werden schließlich Konsensentscheidungen treffen.
Natürlich sind Gruppenregeln möglicherweise nicht korrekt, aber Meinungsführer, die einen Konsens vertreten und im Alleingang einen Konsens herstellen können, sind absolute Super-Individuen. Doch in den meisten Fällen strebt der Konsens nicht die vollständige und bedingungslose Zustimmung aller an, sondern erfordert lediglich die allgemeine Anerkennung der Gruppe.
Wir sind nicht hier, um darüber zu diskutieren, ob KI die Menschen in die Irre führen wird. Tatsächlich gibt es bereits viele solcher Diskussionen, ob es die große Menge an Müll ist, der durch Anwendungen der künstlichen Intelligenz erzeugt wird, die die Authentizität von Netzwerkdaten verunreinigt hat, oder die Fehler in der Gruppe Entscheidungen, die zu einigen führen werden Der Vorfall nahm eine gefährlichere Wendung.
Die aktuelle Situation der KI weist ein natürliches Monopol auf. Beispielsweise erfordern das Training und der Einsatz großer Modelle eine große Menge an Rechenressourcen und Daten, und nur wenige Unternehmen und Institutionen verfügen über diese Bedingungen. Diese Milliarden von Daten werden von jedem Monopolbesitzer als Schätze betrachtet, ganz zu schweigen vom Open-Source-Sharing, selbst ein gegenseitiger Zugriff ist unmöglich.
Dies führt zu einer enormen Datenverschwendung. Ob es sich um Fusionen und Übernahmen, Verkäufe, die Erweiterung einzelner Riesenprojekte oder das traditionelle Internet handelt . Die Logik des Rodeo-Rennens.
Viele Leute sagen, dass KI und Web3 überhaupt nichts miteinander zu tun haben. Die erste Hälfte des Satzes ist richtig, aber die zweite Hälfte des Satzes ist problematisch Das Monopol der künstlichen Intelligenz wird enden. Und der Einsatz künstlicher Intelligenztechnologie zur Förderung der Bildung eines dezentralen Konsensmechanismus ist einfach eine natürliche Sache.
Schlussfolgerung auf der untersten Ebene: Lassen Sie die KI einen wirklich verteilten Gruppenkonsensmechanismus bilden
Der Kern der künstlichen Intelligenz liegt immer noch im Menschen selbst. Maschinen und Modelle sind nur Spekulationen und Nachahmungen menschlichen Denkens. Die sogenannte Gruppe lässt sich eigentlich nur schwer von der Gruppe abstrahieren, denn was wir jeden Tag sehen, sind echte Individuen. Aber das Modell nutzt riesige Datenmengen zum Lernen und Anpassen und simuliert schließlich die Gruppenform. Es ist nicht notwendig, die Ergebnisse dieses Modells zu bewerten, da Vorfälle von Gruppenübelkeit nicht ein- oder zweimal passieren. Aber das Modell repräsentiert die Entstehung dieses Konsensmechanismus.
Wenn beispielsweise für ein bestimmtes DAO die Governance als Mechanismus implementiert wird, wirkt sich dies zwangsläufig auf die Effizienz aus. Der Grund dafür ist, dass die Bildung eines Gruppenkonsenses eine problematische Sache ist, ganz zu schweigen von Abstimmungen, Statistiken usw. Serie Operationen. Wenn die Governance des DAO in Form eines KI-Modells verkörpert ist und die gesamte Datenerfassung auf den Sprachdaten aller Mitglieder des DAO basiert, werden die Ausgabeentscheidungen tatsächlich eher dem Gruppenkonsens entsprechen.
Der Gruppenkonsens eines einzelnen Modells kann verwendet werden, um das Modell gemäß dem obigen Schema zu trainieren, aber für diese Individuen handelt es sich letztendlich immer noch um isolierte Inseln. Wenn es ein kollektives Intelligenzsystem zur Bildung einer Gruppen-KI gibt, wird jedes KI-Modell in diesem System zusammenarbeiten, um komplexe Probleme zu lösen, was tatsächlich eine große Rolle bei der Stärkung der Konsensebene spielt.
Für kleine Sammlungen können Sie unabhängig ein Ökosystem aufbauen oder eine kooperative Gruppe mit anderen Sammlungen bilden, um extrem große Rechenleistung oder Datentransaktionen effizienter und kostengünstiger zu bewältigen. Aber die aktuelle Situation zwischen verschiedenen Modelldatenbanken ist völliges Misstrauen und Schutz vor anderen. Dies ist die natürliche Eigenschaft der Blockchain: Durch Misstrauen kann eine wirklich verteilte Sicherheit zwischen KI-Maschinen erreicht werden.

Ein globales intelligentes Gehirn kann dazu führen, dass KI-Algorithmusmodelle, die ursprünglich unabhängig voneinander sind und einzelne Funktionen haben, miteinander kooperieren und intern komplexe intelligente Algorithmusprozesse ausführen, um kontinuierlich ein verteiltes Gruppenkonsensnetzwerk zu bilden. Dies ist auch die größte Bedeutung der Stärkung von Web3 durch KI.
Privatsphäre und Datenmonopol? Die Kombination aus ZK und maschinellem Lernen
Der Mensch muss aus Gründen des Datenschutzes gezielte Vorkehrungen gegen die bösen Taten der KI oder die Angst vor einem Datenmonopol treffen. Das Kernproblem besteht darin, dass wir nicht wissen, wie zu der Schlussfolgerung gelangt wird. Ebenso haben die Betreiber des Modells nicht die Absicht, Fragen zu diesem Problem zu beantworten. Für die oben erwähnte Integration des globalen intelligenten Gehirns muss dieses Problem noch mehr gelöst werden, sonst wird keine Datenpartei bereit sein, ihren Kern mit anderen zu teilen.
ZKML (Zero Knowledge Machine Learning) ist eine Technologie, die wissensfreie Beweise für maschinelles Lernen verwendet. Zero-Knowledge Proofs (ZKP) bedeutet, dass der Prüfer den Prüfer von der Authentizität der Daten überzeugen kann, ohne die spezifischen Daten preiszugeben.

Nehmen Sie theoretische Fälle als Leitfaden. Es gibt ein 9×9-Standard-Sudoku. Die Abschlussbedingung besteht darin, die neun Felder mit Zahlen von 1 bis 9 auszufüllen, sodass jede Zahl in jeder Zeile, Spalte und jedem Gitter nur einmal vorkommen darf. Wie beweist die Person, die dieses Rätsel erstellt hat, den Herausforderern, dass das Sudoku eine Lösung hat, ohne die Antwort preiszugeben?

Bedecken Sie einfach die Füllfläche mit der Antwort und lassen Sie den Herausforderer dann zufällig ein paar Zeilen oder Spalten auswählen, alle Zahlen mischen und überprüfen, ob sie alle eins bis neun sind. Dies ist eine einfache Implementierung des wissensfreien Beweises.
Die Zero-Knowledge-Proof-Technologie weist drei Merkmale auf: Vollständigkeit, Korrektheit und Zero-Knowledge, was bedeutet, dass sie die Schlussfolgerung beweist, ohne irgendwelche Details preiszugeben. Seine technische Quelle kann die Einfachheit widerspiegeln. Im Kontext der homomorphen Verschlüsselung ist die Schwierigkeit der Überprüfung viel geringer als die Schwierigkeit, Beweise zu generieren.
Beim maschinellen Lernen werden Algorithmen und Modelle verwendet, damit Computersysteme aus Daten lernen und sich verbessern können. Durch automatisiertes Lernen aus Erfahrungen kann das System automatisch Aufgaben wie Vorhersage, Klassifizierung, Clustering und Optimierung auf der Grundlage von Daten und Modellen ausführen.
Im Kern besteht maschinelles Lernen darin, Modelle zu erstellen, die aus Daten lernen und automatisch Vorhersagen und Entscheidungen treffen. Die Konstruktion dieser Modelle erfordert normalerweise drei Schlüsselelemente: Datensätze, Algorithmen und Modellbewertung. Datensätze sind die Grundlage des maschinellen Lernens und enthalten Datenbeispiele, die zum Trainieren und Testen von Modellen für maschinelles Lernen verwendet werden. Algorithmen sind der Kern von Modellen für maschinelles Lernen und definieren, wie das Modell aus Daten lernt und Vorhersagen trifft. Die Modellbewertung ist ein wichtiger Teil des maschinellen Lernens. Sie wird verwendet, um die Leistung und Genauigkeit des Modells zu bewerten und zu entscheiden, ob das Modell optimiert und verbessert werden muss.

Beim herkömmlichen maschinellen Lernen müssen Datensätze für das Training normalerweise an einem zentralen Ort gesammelt werden. Dies bedeutet, dass der Dateneigentümer die Daten mit Dritten teilen muss, was zu einem Risiko von Datenlecks oder Datenschutzverlusten führen kann. Mit ZKML können Dateneigentümer Datensätze mit anderen teilen, ohne dass die Daten verloren gehen. Dies wird durch die Verwendung von Zero-Knowledge-Proofs erreicht.
Wenn Zero-Knowledge-Proof verwendet wird, um maschinelles Lernen zu ermöglichen, sollte der Effekt vorhersehbar sein. Dies löst das seit langem bestehende Problem der Datenschutz-Blackbox und des Datenmonopols: ob die Projektpartei dies tun kann, ohne Benutzerdateneingaben oder spezifische Details preiszugeben Kann jede Sammlung nach Abschluss des Nachweises und der Verifizierung ihre eigenen Daten oder Modelle teilen, ohne dass private Daten verloren gehen? Natürlich ist die aktuelle Technologie noch am Anfang und es wird in der Praxis definitiv viele Probleme geben. Dies hindert uns nicht daran, uns das vorzustellen, und viele Teams entwickeln sie bereits.
Wird diese Situation zur kostenlosen Prostitution kleiner Datenbanken gegenüber großen Datenbanken führen? Wenn Sie über Governance-Themen nachdenken, kehren Sie zu unserem Web3-Denken zurück. Die Essenz von Crypto ist Governance. Ob durch umfangreiche Nutzung oder Teilen, es sollten angemessene Anreize erhalten. Ob durch die ursprünglichen Pow-, PoS-Mechanismen oder die neuesten verschiedenen PoR-Mechanismen (Proof of Reputation), die Anreizwirkung ist garantiert.
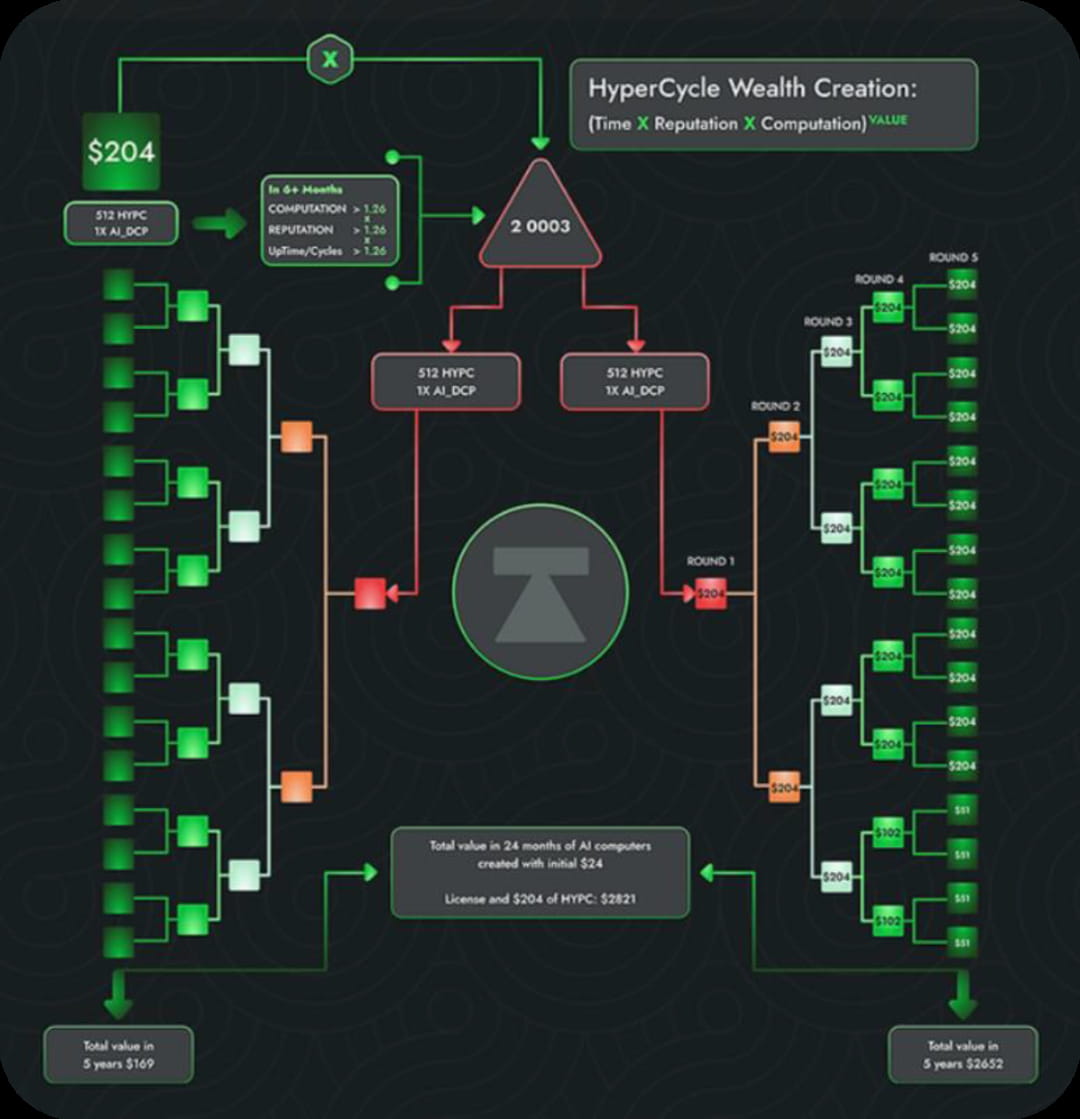
Verteilte Rechenleistung: eine innovative Erzählung, die mit Lügen und Realität verflochten ist
Dezentrale Rechenleistungsnetzwerke waren schon immer ein beliebtes Szenario im Verschlüsselungskreis. Schließlich erfordern große KI-Modelle eine erstaunliche Rechenleistung, und zentralisierte Rechenleistungsnetzwerke werden nicht nur eine Verschwendung von Ressourcen verursachen, sondern im Vergleich zu In auch ein virtuelles Monopol bilden Am Ende zählt nur die Anzahl der GPUs, was zu langweilig ist.
Der Kern eines dezentralen Computernetzwerks besteht darin, über verschiedene Standorte und Geräte verteilte Computerressourcen zu integrieren. Die wichtigsten Vorteile, die jeder häufig nennt, sind die Bereitstellung verteilter Rechenfunktionen, die Lösung von Datenschutzproblemen, die Verbesserung der Glaubwürdigkeit und Zuverlässigkeit von Modellen der künstlichen Intelligenz, die Unterstützung einer schnellen Bereitstellung und des Betriebs in verschiedenen Anwendungsszenarien sowie die Bereitstellung dezentraler Datenspeicher- und Verwaltungslösungen. Richtig, durch dezentrale Rechenleistung kann jeder KI-Modelle ausführen und sie an echten On-Chain-Datensätzen von globalen Benutzern testen, sodass er flexiblere, effizientere und kostengünstigere Computerdienste nutzen kann.

Gleichzeitig kann die dezentrale Rechenleistung Datenschutzprobleme lösen, indem sie einen leistungsstarken Rahmen zum Schutz der Sicherheit und Privatsphäre der Benutzerdaten schafft. Es bietet außerdem einen transparenten und überprüfbaren Rechenprozess, erhöht die Glaubwürdigkeit und Zuverlässigkeit von Modellen der künstlichen Intelligenz und stellt flexible und skalierbare Rechenressourcen für eine schnelle Bereitstellung und einen schnellen Betrieb in verschiedenen Anwendungsszenarien bereit.
Wir betrachten das Modelltraining aus einem vollständigen Satz zentralisierter Rechenprozesse. Die Schritte sind normalerweise unterteilt in: Datenvorbereitung, Datensegmentierung, Datenübertragung zwischen Geräten, paralleles Training, Gradientenaggregation, Parameteraktualisierung, Synchronisierung und wiederholtes Training. Selbst wenn in diesem Prozess ein zentraler Computerraum einen Cluster von Hochleistungscomputergeräten verwendet, um Computeraufgaben über Hochgeschwindigkeitsnetzwerkverbindungen zu teilen, sind die hohen Kommunikationskosten zu einer der größten Einschränkungen dezentraler Computernetzwerke geworden.
Obwohl das dezentrale Rechenleistungsnetzwerk viele Vorteile und Potenziale bietet, ist der Entwicklungspfad daher angesichts der aktuellen Kommunikationskosten und der tatsächlichen Betriebsschwierigkeiten immer noch mühsam. In der Praxis erfordert die Realisierung eines dezentralen Computernetzwerks die Überwindung vieler praktischer technischer Probleme, sei es die Gewährleistung der Zuverlässigkeit und Sicherheit von Knoten, die effektive Verwaltung und Planung verteilter Computerressourcen oder die Erzielung einer effizienten Datenübertragung und Kommunikation usw. , sind wahrscheinlich alles große Probleme, mit denen wir in der Praxis konfrontiert sind.
Schwanz: Erwartungen bleiben für Idealisten bestehen
Zurück zur Geschäftsrealität: Das Narrativ der tiefen Integration von KI und Web3 sieht so gut aus, aber Kapital und Benutzer sagen uns mit praktischeren Maßnahmen, dass dies eine äußerst schwierige Innovationsreise sein wird, es sei denn, das Projekt kann wie OpenAI sein. Obwohl wir stark sind, sollten wir einen starken Sponsor unterstützen, sonst werden uns die grenzenlosen Forschungs- und Entwicklungskosten und das unklare Geschäftsmodell völlig zerstören.
Sowohl KI als auch Web3 befinden sich derzeit in einem äußerst frühen Entwicklungsstadium, genau wie die Internetblase am Ende des letzten Jahrhunderts. Erst fast zehn Jahre später wurde das wahre goldene Zeitalter offiziell eingeläutet. McCarthy träumte einmal davon, in einem Urlaub künstliche Intelligenz mit menschlicher Intelligenz zu entwickeln, aber erst fast siebzig Jahre später machten wir tatsächlich einen entscheidenden Schritt in Richtung künstlicher Intelligenz.
Dasselbe gilt für Web3+AI. Wir haben die Richtigkeit der Richtung nach vorne bestimmt, und der Rest wird der Zeit überlassen.
Wenn sich die Zeit allmählich zurückzieht, sind die Menschen und Dinge, die stehen bleiben, die Eckpfeiler unserer Reise von der Science-Fiction zur Realität.