
Bereitstellung präziser, konsistenter und produktionsbereiter Funktionen für maschinelles Lernen.

In diesem Artikel wird unser Feature Store für maschinelles Lernen (ML) genauer untersucht. Es ist eine Fortsetzung unseres vorherigen Blogbeitrags, der einen breiteren Überblick über die gesamte ML-Pipeline-Infrastruktur bietet.
Warum verwenden wir einen Feature Store?
Der Feature Store, einer der vielen Teile in unserer Pipeline, ist wohl das wichtigste Rädchen im System. Sein Hauptzweck besteht darin, als zentrale Datenbank zu fungieren, die Features verwaltet, bevor sie zum Modelltraining oder zur Inferenz versendet werden.
Falls Sie mit dem Begriff nicht vertraut sind: Bei Features handelt es sich im Wesentlichen um Rohdaten, die durch einen Prozess namens „Feature Engineering“ in etwas Nutzbareres verfeinert werden, das unsere ML-Modelle verwenden können, um sich selbst zu trainieren oder Vorhersagen zu berechnen.
Kurz gesagt ermöglichen uns Feature Stores:
Wiederverwenden und gemeinsame Nutzung von Funktionen über verschiedene Modelle und Teams hinweg
Verkürzen Sie die für ML-Experimente erforderliche Zeit
Minimieren Sie ungenaue Vorhersagen aufgrund einer starken Trainings-Serving-Verzerrung
Um die Bedeutung eines Feature Stores besser zu verstehen, sehen Sie hier ein Diagramm einer ML-Pipeline, die keinen verwendet.
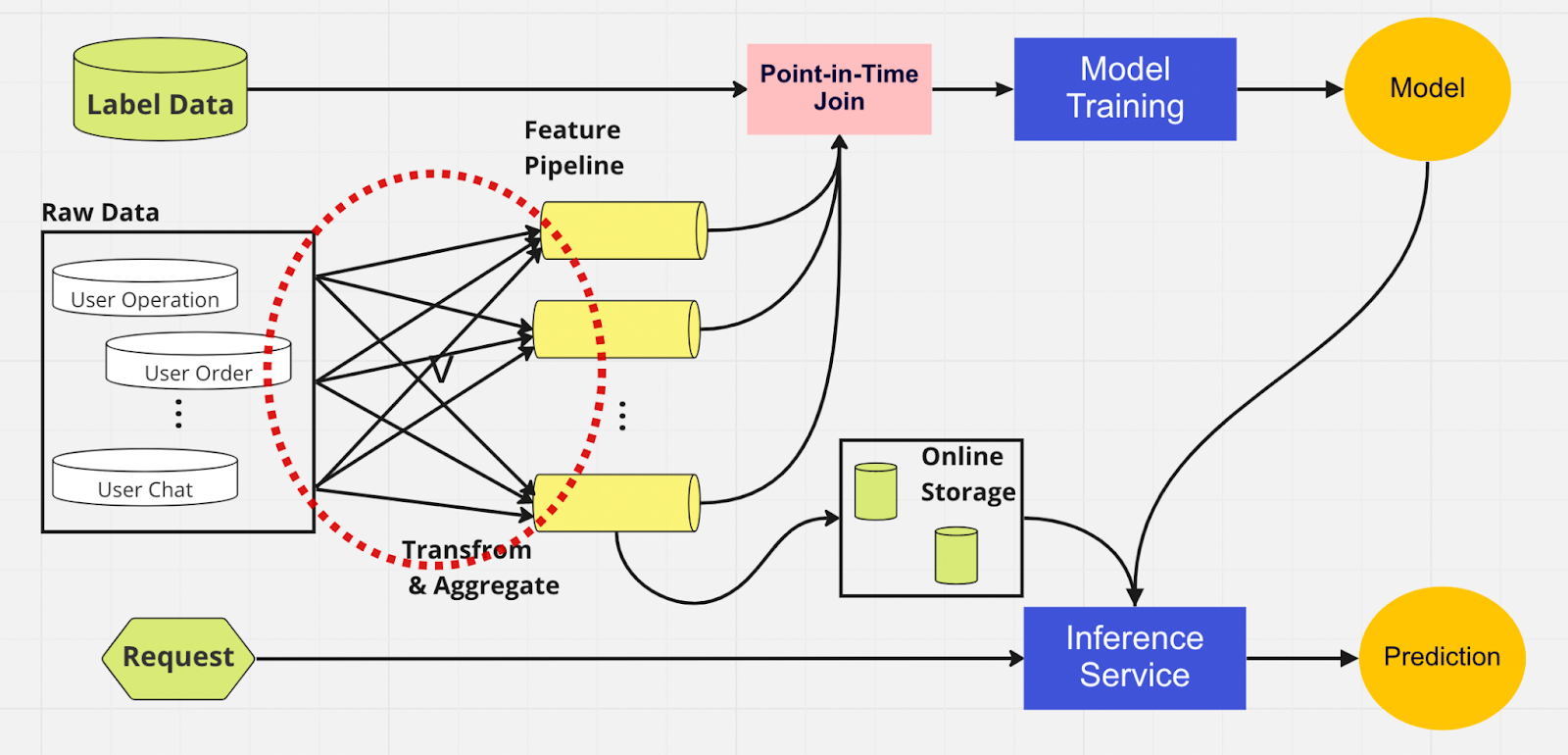
In dieser Pipeline können die beiden Teile – Modelltraining und Inferenzdienst – nicht erkennen, welche Features bereits vorhanden sind und wiederverwendet werden können. Dies führt dazu, dass die ML-Pipeline den Feature-Engineering-Prozess dupliziert. Sie werden im roten Kreis im Diagramm bemerken, dass die ML-Pipeline, anstatt Features wiederzuverwenden, eine Ansammlung doppelter Features und redundanter Pipelines erstellt hat. Wir nennen diese Ansammlung eine Feature-Pipeline-Ausbreitung.
Die Wartung dieser Vielzahl von Funktionen wird mit dem Wachstum des Unternehmens und der Nutzung der Plattform durch mehr Benutzer zu einem immer teureren und unüberschaubareren Szenario. Betrachten Sie es so: Der Datenwissenschaftler muss den langwierigen und mühsamen Feature-Engineering-Prozess für jedes neue Modell, das er erstellt, von Grund auf neu starten.
Darüber hinaus führt eine zu häufige Neuimplementierung der Feature-Logik zu einem Konzept namens „Training-Serving Skew“, also einer Diskrepanz zwischen Daten während der Trainings- und Inferenzphase. Dies führt zu ungenauen Vorhersagen und unvorhersehbarem Modellverhalten, das während der Produktion nur schwer zu beheben ist. Vor der Einführung von Feature Stores überprüften unsere Datenwissenschaftler die Feature-Konsistenz mithilfe von Plausibilitätsprüfungen. Dies ist ein manueller, zeitaufwändiger Prozess, der die Aufmerksamkeit von Aufgaben mit höherer Priorität wie Modellierung und aufschlussreicher Feature-Entwicklung ablenkt. Sehen wir uns nun eine ML-Pipeline mit einem Feature Store an.

Ähnlich wie bei der anderen Pipeline haben wir auf der linken Seite dieselben Datenquellen und Features. Anstatt jedoch mehrere Feature-Pipelines zu durchlaufen, haben wir den Feature Store als zentralen Hub, der beide Phasen der ML-Pipeline (Modelltraining und Inferenzdienst) bedient. Es gibt keine doppelten Features; alle zum Erstellen eines Features erforderlichen Prozesse, einschließlich Transformation und Aggregation, müssen nur einmal ausgeführt werden.
Datenwissenschaftler können mithilfe unseres benutzerdefinierten Python SDK intuitiv mit dem Feature Store interagieren, um Features für das nachgelagerte Training und die Inferenz von ML-Modellen zu suchen, wiederzuverwenden und zu entdecken.
Im Wesentlichen ist der Feature Store eine zentrale Datenbank, die beide Phasen vereint. Und da der Feature Store konsistente Features für Training und Inferenz garantiert, können wir die Abweichung zwischen Training und Bereitstellung erheblich reduzieren.
Beachten Sie, dass Feature Stores noch viel mehr können als die oben genannten Punkte. Dies ist natürlich eine eher rudimentäre Zusammenfassung, warum wir einen Feature Store verwenden, und eine, die wir in nur wenigen Worten weiter aufschlüsseln können: Features so schnell und einfach wie möglich vorbereiten und in ML-Modelle senden.
Im Feature Store

Die obige Abbildung zeigt Ihr typisches Feature Store-Layout, sei es AWS SageMaker Feature Store, Google Vertex AI (Feast), Azure (Feathr), Iguazio oder Tetcom. Alle Feature Stores bieten zwei Speicherarten: online oder offline.
Online-Feature-Stores werden für Echtzeit-Inferenzen verwendet, während Offline-Feature-Stores für Batch-Vorhersagen und Modelltraining verwendet werden. Aufgrund der unterschiedlichen Anwendungsfälle ist die Metrik, die wir zur Leistungsbewertung verwenden, völlig unterschiedlich. Bei einem Online-Feature suchen wir nach geringer Latenz. Für Offline-Feature-Stores wollen wir einen hohen Durchsatz.
Entwickler können je nach Technologie-Stack jeden beliebigen Enterprise-Feature-Store oder sogar Open Source auswählen. Das folgende Diagramm zeigt die wichtigsten Unterschiede zwischen den Online- und Offline-Stores im AWS SageMaker Feature Store.

Online-Shop: Speichert die neueste Kopie der Funktionen und stellt sie mit geringer Latenz im Millisekundenbereich bereit, deren Geschwindigkeit von der Größe Ihrer Nutzlast abhängt. Für unser Account-Takeover-Modell (ATO), das insgesamt acht Funktionsgruppen und 55 Funktionen umfasst, beträgt die Geschwindigkeit etwa 30 ms p99-Latenz.
Offline-Speicher: Ein Nur-Anhängen-Speicher, der Ihnen die Verfolgung aller historischen Features ermöglicht und Zeitreisen ermöglicht, um Datenverluste zu vermeiden. Daten werden im Parquet-Format mit Zeitpartitionierung gespeichert, um die Leseleistung zu erhöhen.
Was die Funktionskonsistenz betrifft, werden die Daten automatisch und intern in den Offlinespeicher kopiert, während die Funktion vom Onlinespeicher aufgenommen wird, solange die Funktionsgruppe sowohl für die Online- als auch für die Offlineverwendung konfiguriert ist.
Wie nutzen wir den Feature Store?

Der oben abgebildete Code verbirgt eine Menge Komplexität. Feature-Stores ermöglichen uns, die Python-Schnittstelle für das Modelltraining und die Inferenz einfach zu importieren.
Mithilfe des Feature Store können unsere Datenwissenschaftler problemlos Features definieren und neue Modelle erstellen, ohne sich um den langwierigen Datenengineering-Prozess im Backend kümmern zu müssen.
Bewährte Methoden für die Verwendung eines Feature Stores
In unserem vorherigen Blogbeitrag haben wir erklärt, wie wir eine Store-Ebene verwenden, um Features in die zentrale Datenbank zu leiten. Hier möchten wir zwei Best Practices für die Verwendung eines Feature Stores vorstellen:
Wir nehmen keine Features auf, die sich nicht geändert haben
Wir trennen die Funktionen in zwei logische Gruppen: aktive Benutzeroperationen und inaktive
Betrachten Sie dieses Beispiel. Angenommen, Sie haben für PutRecord in Ihrem Online-Feature-Store eine Drosselungsgrenze von 10.000 TPS. In diesem hypothetischen Fall nehmen wir Features für 100 Millionen Benutzer auf. Wir können sie nicht alle auf einmal aufnehmen und bei unserer aktuellen Geschwindigkeit würde es etwa 2,7 Stunden dauern, bis es abgeschlossen ist. Um dieses Problem zu lösen, nehmen wir nur kürzlich aktualisierte Features auf. Beispielsweise nehmen wir ein Feature nicht auf, wenn sich der Wert seit der letzten Aufnahme nicht geändert hat.
Zum zweiten Punkt nehmen wir an, Sie fassen eine Reihe von Features in einer logischen Featuregruppe zusammen. Einige davon sind aktiv, während ein großer Teil inaktiv ist, d. h. die meisten Features sind unverändert. Der logische Schritt besteht unserer Meinung nach darin, aktive und inaktive Features in zwei Featuregruppen aufzuteilen, um den Aufnahmeprozess zu beschleunigen.
Bei inaktiven Features reduzieren wir 95 % der Daten, die wir für 100 Millionen Benutzer pro Stunde in den Feature Store aufnehmen müssen. Außerdem reduzieren wir immer noch 20 % der Daten, die für aktive Features erforderlich sind. Statt drei Stunden verarbeitet die Batch-Aufnahme-Pipeline Features für 100 Millionen Benutzer also in 10 Minuten.
Abschließende Gedanken
Zusammenfassend lässt sich sagen, dass wir mit Feature Stores Features wiederverwenden, die Feature-Entwicklung beschleunigen und ungenaue Vorhersagen minimieren können – und dabei gleichzeitig die Konsistenz zwischen Training und Inferenz aufrechterhalten können.
Sie möchten ML nutzen, um das weltweit größte Krypto-Ökosystem und seine Benutzer zu schützen? Dann sehen Sie sich auf unserer Karriereseite Binance Engineering/AI an, um offene Stellenangebote zu finden.
Weiterführende Literatur:
(Blog) Verwenden von MLOps zum Erstellen einer End-to-End-Pipeline für maschinelles Lernen in Echtzeit