At Binance, we use machine learning (ML) to solve various business problems, including but not limited to account takeover (ATO) fraud, P2P scams, and stolen payment details.
Using machine learning operations (MLOps), our Binance Risk AI data scientists have built a real-time end-to-end ML pipeline that continually delivers production-ready ML services.

For starters, creating an ML service is an iterative process. Data scientists constantly experiment to improve a specific metric, either offline or online, based on the objective of delivering value for the business. So how can we enable this process to be more efficient — for example, shortening the ML model's time-to-market?
Secondly, ML services' behavior is affected not only by the code we, the developers, define but also by the data it collects. This idea, also known as concept drift, is emphasized in Google's paper titled Hidden Technical Debt in Machine Learning Systems.
Take fraud as an example; the scammer is not just a machine but a human that adapts and constantly changes how they attack. As such, the underlying data distribution will evolve to mirror the changes in attack vectors. How can we effectively ensure the production model considers the latest data pattern?
To overcome the challenges mentioned above, we use a concept called MLOps, a term initially proposed by Google in 2018. In MLOps, we focus on the model's performance and the infrastructure supporting the production system. This allows us to build ML services that are scalable, highly available, reliable, and maintainable.
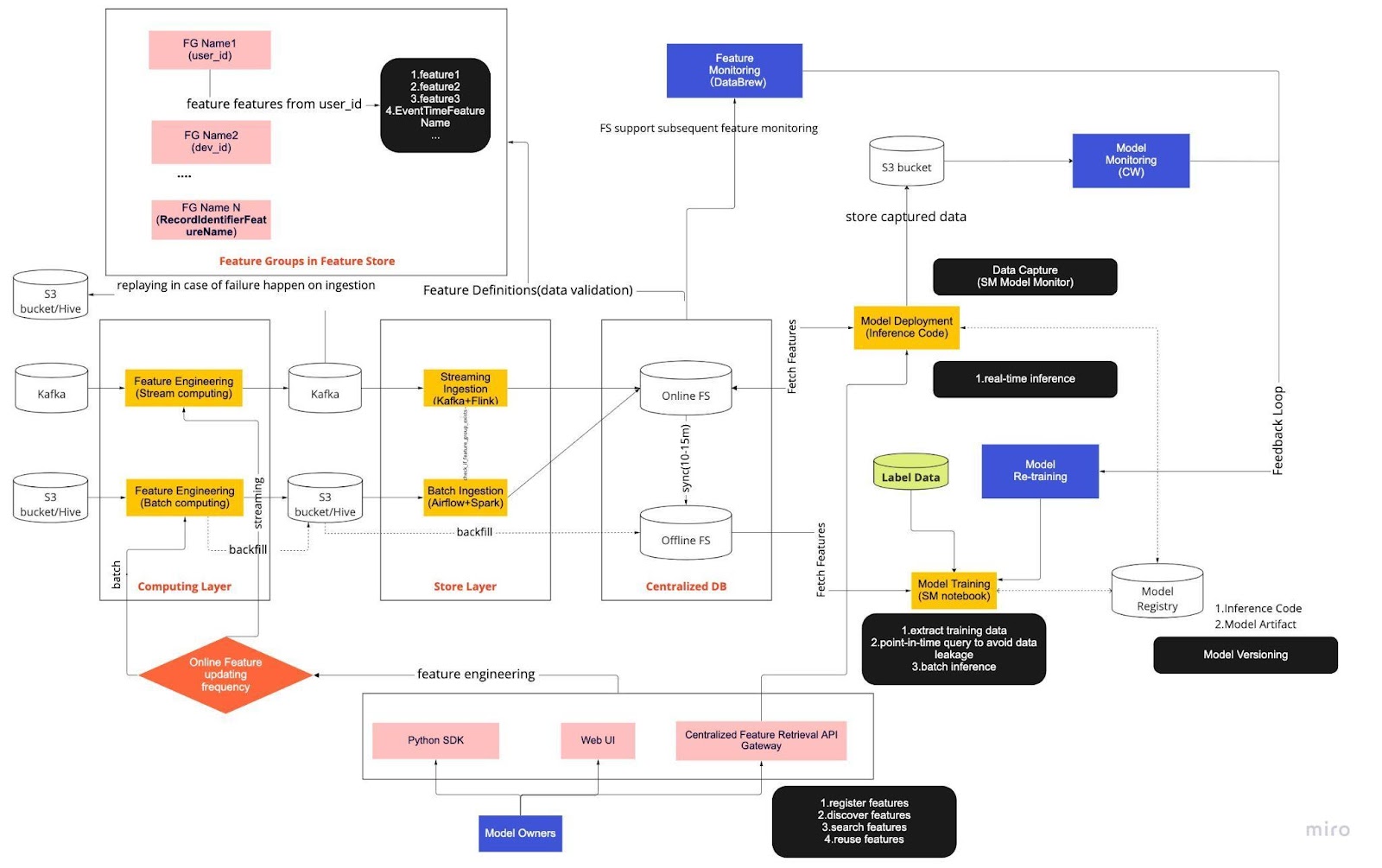
Think of the above diagram as our standard operating procedure (SOP) for real-time model development with a feature store. The end-to-end ML pipeline dictates how our team applies MLops, and it's built with two types of requirements: functional and non-functional.
Functional
Data Processing
Model Training
Model Development
Model Deployment
Monitoring
Non-functional requirements
Scalable
Highly-available
Reliable
Maintainable
The pipeline is further divided into six key components:
Computing layer
Store Layer
Centralized DB
Model Training
Model Deployment
Model Monitoring
1. Computing Layer
The computing layer is mainly responsible for feature engineering, the process of transforming raw data into useful features.
We categorize the computing layer into two types based on the frequency they update: stream computing for one-minute/second intervals and batch computing for daily/hourly intervals.
The computing layer's input data generally comes from the event-based database, which includes Apache Kafka and Kinesis, or the OLAP database, which includes Apache Hive for open-source and Snowflake for cloud solutions.
2. Store Layer
The store layer is where we register feature definitions and deploy them into our feature store as well as perform backfill, a process that allows us to rebuild features via historical data whenever a new feature is defined. Backfill is typically a one-time job our data scientists can do in a notebook environment. Because Kafka can only store events from the last seven days, it employs a backup mechanism into the s3/hive table to increase fault tolerance.
You'll notice the intermediate layer, Hive and Kafka, is deliberately housed between the computing and store layers. Think of this placement as a buffer between computing and writing features. An analogy would be separating the producer from the consumer. Stream computing is the producer, while stream ingestion is the consumer.
Decoupling computing and ingestion provides a variety of benefits for our ML pipelines. For starters, we can increase the pipeline's robustness in case of failures. Our data scientists can still pull feature value from the centralized database, even if the ingestion or computing layer is unavailable due to operational, hardware, or network issues.
Furthermore, we can scale different parts of the infrastructure individually and reduce the energy required to build and operate the pipeline. For instance, if it fails for whatever reason, the ingestion layer won't block the computing layer. On the innovation front, we can experiment and adopt new technology, such as a new version of the Flink application, without affecting our existing infrastructure.
Both the computing layer and the store layer are what we call automated feature pipelines. These pipelines are independent, run on varying schedules, and are categorized as streaming or batch pipelines. Here's how the two pipelines work differently: one feature group in a batch pipeline might refresh nightly while another group is updated hourly. In a streaming pipeline, the feature group updates in real-time as source data arrives on an input stream, such as an Apache Kafka topic.
3. Centralized DB
The centralized DB layer is where our data scientists present their feature-ready data into an online or offline feature store.
The online feature store is a low latency, high-availability store that enables real-time look-up of records. On the other hand, the offline feature store provides a secure and scalable repository of all feature data. This allows scientists to create training, validation, or batch-scoring datasets from a set of centrally-managed feature groups with a full historical record of feature values in the object storage system.
Both feature stores automatically synchronize with each other every 10-15 minutes to avoid training-serving skew. In a future article, we'll do a deep dive into how we use feature stores in the pipelines.
4. Model Training
The model training layer is where our scientists extract training data from the offline feature store to finetune our ML services. We use point-in-time queries to prevent data from leaking during the extraction process.
Additionally, this layer includes a crucial component known as a model-retraining feedback loop. Model-retraining minimizes the risk of concept drift by ensuring deployed models accurately represent the latest data patterns — for example, a hacker changing their attack behavior.
5. Model Deployment
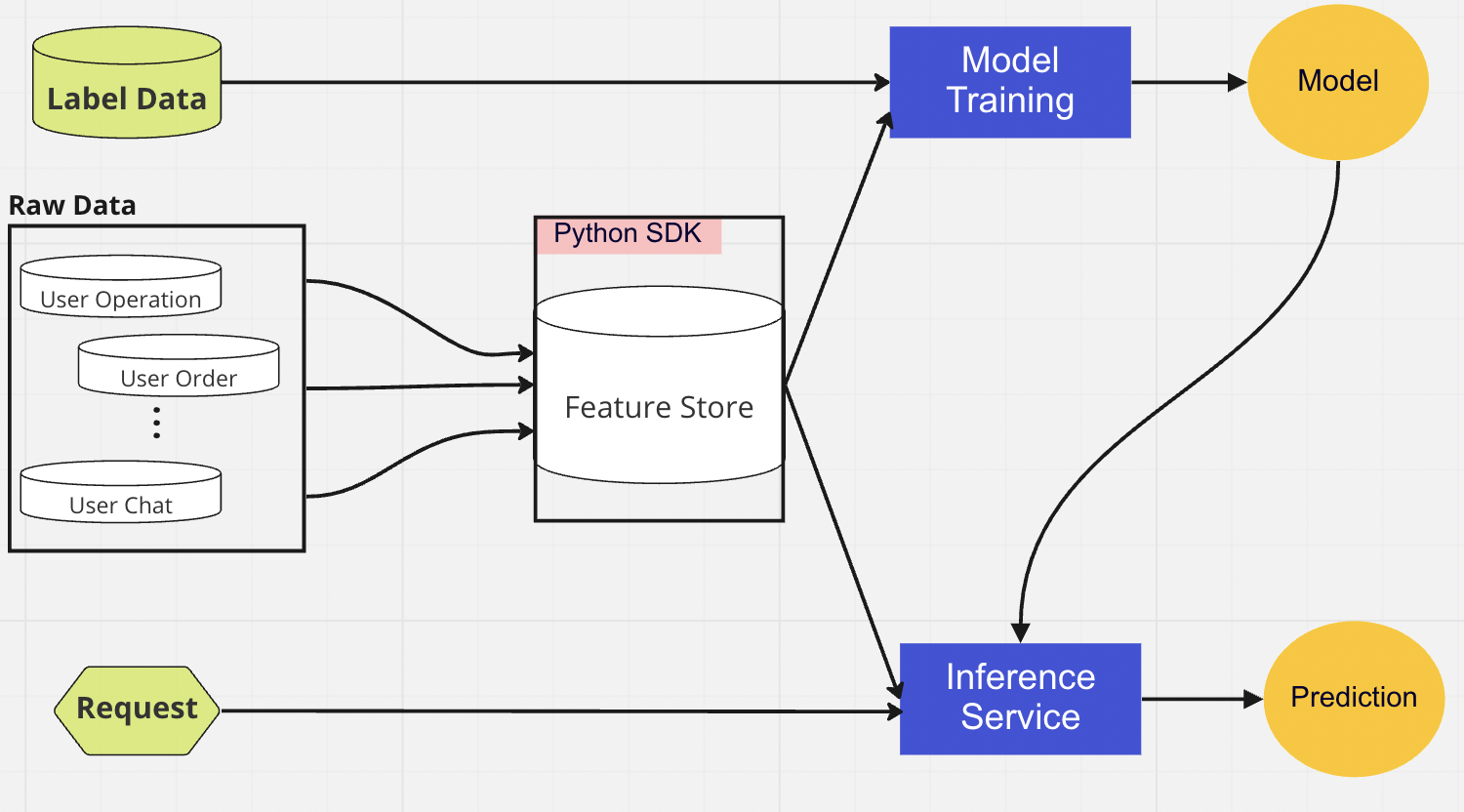
For model deployment, we primarily use a cloud-based scoring service as the backbone of our real-time data serving. Here's a diagram showing how the current inference code integrates with the feature store.
6. Model Monitoring
In this layer, our team monitors the usage metrics for scoring services such as QPS, latency, memory, and CPU/GPU utilization rate. Besides these basic metrics, we use captured data to check feature distribution over time, training-serving skew, and prediction drift to ensure minimal concept drift.
To wrap up, loosely dividing our pipeline infrastructure into a computing layer, store layer, and centralized DB gives us three key benefits over a more tightly-coupled architecture.
More robust pipelines in case of failures
Increased flexibility in choosing which tools to implement
Independently-scalable components
Interested in using ML to safeguard the world's largest crypto ecosystem and its users? Check out Binance Engineering/AI on our careers page for open job postings.